
Search engine optimization (SEO) includes a variety of tactics that make your website easier to find via search and boost your organic traffic. These strategies are often categorized into three different SEO buckets:
- On-Page SEO
- Tech SEO (a subcategory of On-Page SEO)
- Off-Page SEO
While their overarching goal is the same, the tactics differ within each category. A comprehensive SEO strategy primed to drive results will include all three. However, because the concepts can seem confusing, technical SEO is too often ignored. In this technical SEO guide, I’ll help you better understand what tech SEO is, how to incorporate it into your strategy, and the tech SEO tools you’ll want to add to your toolkit.
What Is Technical SEO?
Technical SEO focuses on making it easier for search engine crawlers to find, crawl, and index your web pages so you can rank in search results.
This can include everything from how you structure your URLs and your internal linking strategy to your use of pop-ups and how your site looks and works on mobile devices.
When you focus on technical optimization, you don’t just make it easier for search engines to find and index your website. Because many of the factors associated with tech SEO have a UX component, they also make your website easier for visitors to navigate and use. This is especially the case with Google’s page experience signals, which I’ll cover below.
Technical SEO Basics
A strategic approach to technical SEO begins before you even launch your website. By planning how you’re going to structure your site and following tech SEO best practices, you can build an SEO-friendly site from the ground up. This allows you to scale while still making it easy for visitors and search engine crawlers to navigate your site.
Website Setup
Whether you’re in the planning phase, or you already have a website, you’ll want to systematically align your choices with current tech SEO best practices.
Here are some important things to consider.
HTTPS
One of the first things to do when establishing a new site is to decide on your protocol: HTTP or HTTPS.
Since Google checks that websites are using HTTPS and has even made it one of its page experience signals, selecting that protocol can save you time and energy down the line. If you haven’t yet launched your website, be sure to purchase a TLS certificate and establish it on the HTTPS protocol. Many hosting companies sell these certificates (often called SSL certificates). Alternatively, you can purchase one from a certification agency.
If you already have an HTTP website, follow these steps to migrate your site to HTTPS.
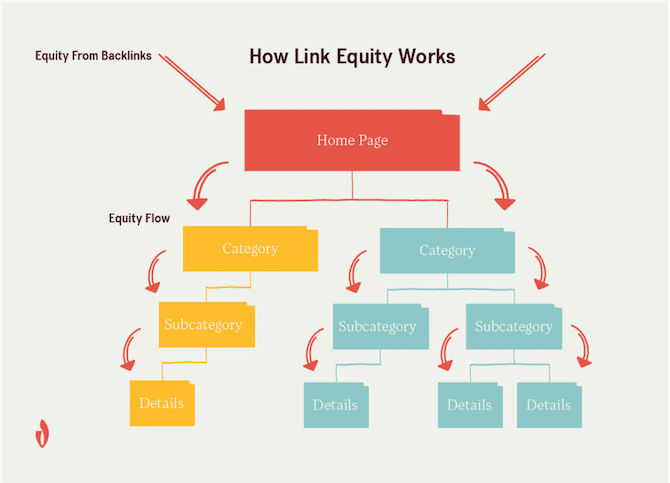
Site Architecture
Your site architecture is how you organize and interlink your web pages. It impacts how easily visitors and search bots can navigate your website. A simple infrastructure makes it easier for visitors to find the content they’re interested in and for web crawlers to find and index all of your pages.
What is a simple website infrastructure?
A simple website infrastructure uses a logical hierarchy to present information in a way that makes sense for humans and search engine bots.
Your homepage should link to the main sections of your website, and those pages should then link to topically related subsections.
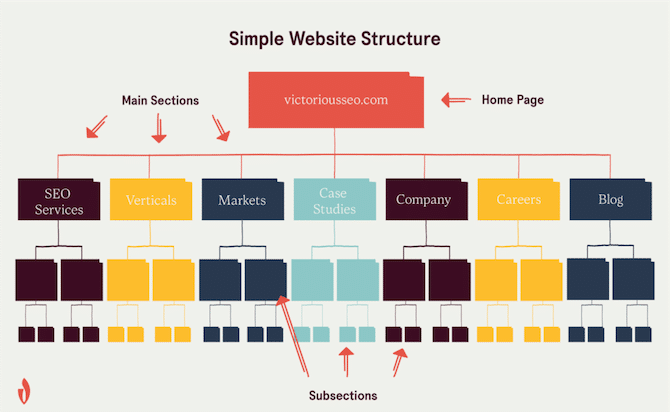
For a more in-depth explanation of of website architecture, check out this article.
Implementing a simple, hierarchical structure like this allows you to strategically pass link equity from your pages and reduce the chances of orphaned pages (important pages that have no internal links pointing to them). It can also make it more likely that your site will receive “Sitelinks” in Google SERPS.
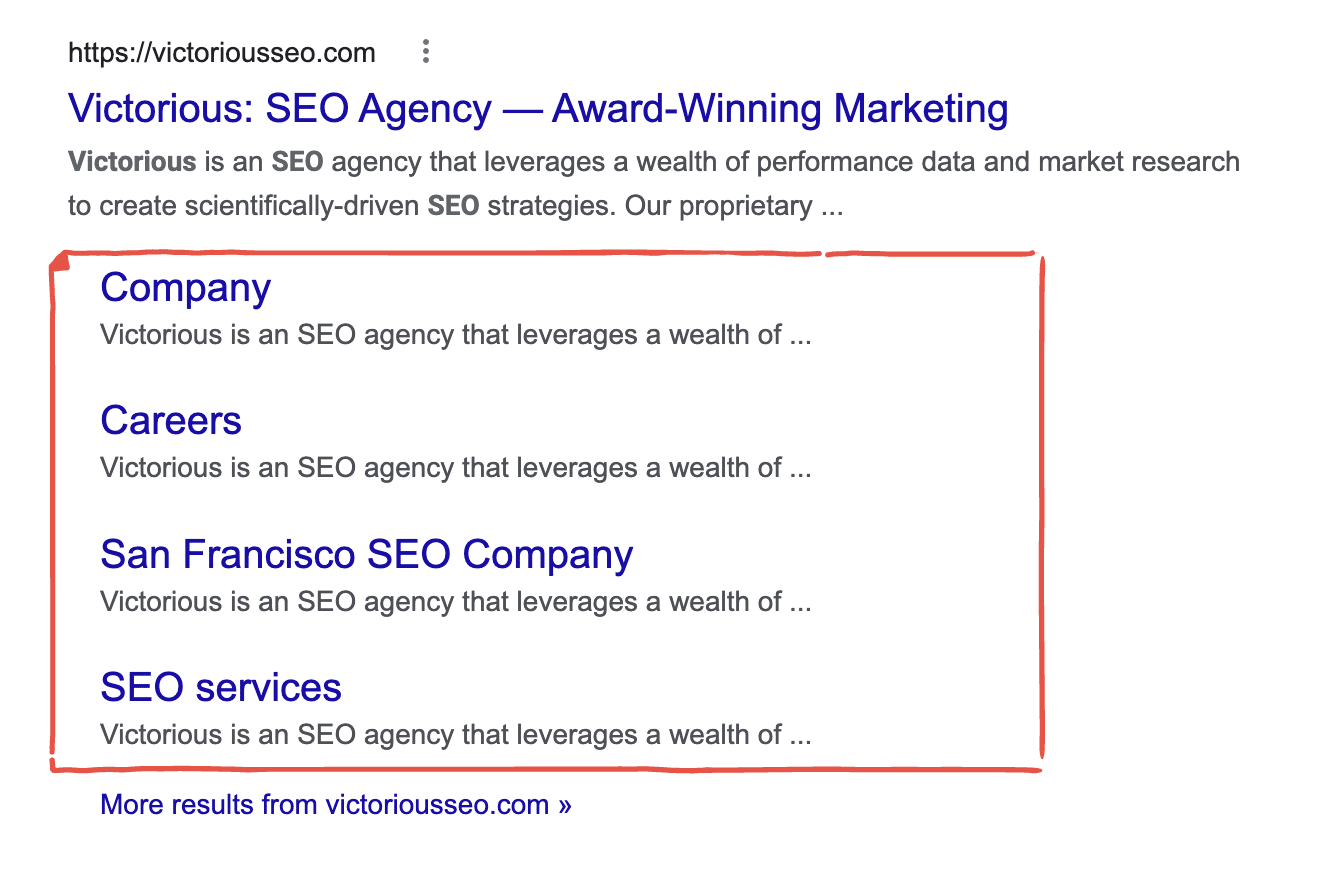
Sitelinks are additional links to your web pages that appear in search results to help users more easily navigate to the page they want. These are automatically generated by Google, but by having a clear site structure, you can increase your chances your sitelinks appear in search.
Subdomain vs. Subdirectory
If you want to host a blog on your site or create an ecommerce shop, decide whether using a subdomain or subdirectory will help you achieve your goals.
Subdomains are subsets of a root domain. You can identify a subdomain in a URL because it comes before the main domain name.
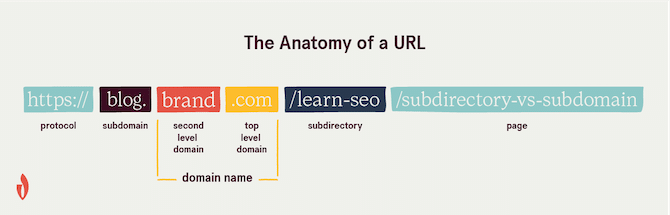
Subdomains are viewed as separate websites by Google, even though they are part of the same root domain. Because of this, there’s the potential that you could have two pages on separate subdomains competing against each other for the same keyword.
Subdirectories live on your main domain and are used to organize your site’s content. They’re like a series of folders. In URLs, the subdirectories come after the main domain.
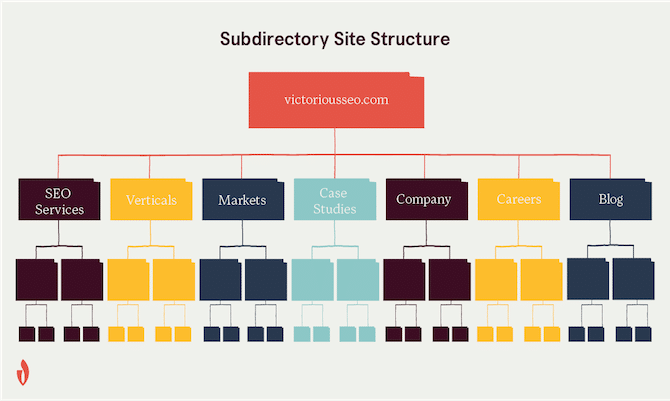
If you want to maximize the value of your content and concentrate the power of your backlink, then it may be best to use subdirectories instead of establishing subdomains. Learn more on our blog about whether to choose a subdomain vs. subdirectory and whether Google will index a subdomain.
URL Structure
Your site architecture informs how you structure your URLs. Each of your subdirectories will have its own subfolders that will be specified in your URLs. When creating pages, use descriptive, keyword-relevant page names. Doing so helps search engines establish a clear, semantic relationship between the different pages on your website and helps users understand where they are on your site.
For example,
https://victoriousseo.com/what-is-seo/on-page/h1-tagsA URL structure like this one signals that your website is well organized, demonstrates expertise in your industry, and tells search engines that you have authoritative, relevant content for anyone looking for information about h1 tags as they relate to SEO.
As you continue to add onto a site with an optimized URL structure, your relevancy signals will solidify, and search engines will assign more value to the content you create. Be sure to include your keyword in your URL to make your page’s topic more obvious.
Avoid using unnecessary numbers like dates or strings of random numbers and letters. These can make your URL more confusing.
If your CMS automatically includes a date in your URL, change the permalink settings so it only uses your chosen slug. This simplifies your URL structure moving forward. If you need to change URLs, like if you move from HTTP to HTTPS or want to standardize your URLS, you’ll need to implement 301 redirects.
Breadcrumbs
Remember the story of Hansel & Gretel? As they’re being led into the forest, Hansel leaves a trail of breadcrumbs which he hopes will guide him and his sister back home. Unfortunately, those delicious morsels get eaten by birds. Despite their ineffectiveness in the Brother’s Grimm fairytale, programmers have integrated the central idea behind the fairytale breadcrumbs into website coding.
So what are breadcrumbs on a website?
Breadcrumbs are a navigational feature on a website that make your site architecture more obvious by showing visitors where they are on your site and how they got there. This text-based path is often found at the top of a page beneath the menu.
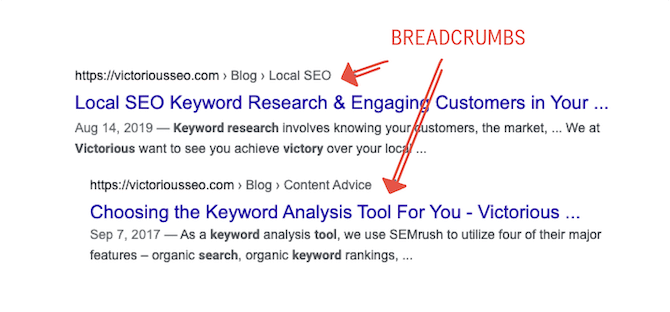
Here’s an example of the breadcrumbs for one of our pages:

This breadcrumb is from our Keyword Research Services page. It clearly shows the Keyword Research page branches off of our SEO Services page, which branches off from our Home Page.
Breadcrumbs create more internal links and highlight how pages relate to each other. (More on internal linking below!)
When implementing breadcrumbs, make use of BreadcrumbList schema. This helps Google better understand your site hierarchy. Plus, it looks nicer in search results.
Learn how to implement breadcrumb schema here.
Error Pages
If someone tries to access a page on your site that doesn’t exist, they should be served a custom 404 error page. Visitors may encounter this error if you remove a page or change its URL without redirecting it or if they mistype a URL.
If you delete a page or change its URL, you need to redirect visitors and search crawlers by implementing a 301 redirect (more on this below). If your old URL has already been indexed and appears in search results, this signals to search engines that it has a new web address and it should replace the old one in search results. Otherwise, Google will deindex the URL returning the 404 error.
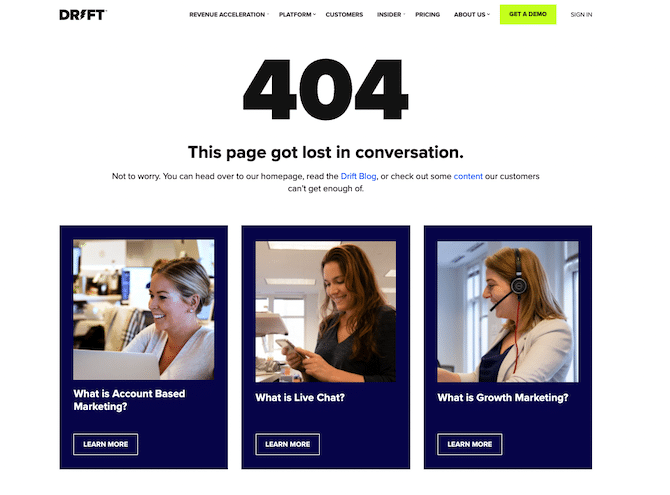
404 errors are going to happen. To reduce the chance that a visitor bounces from your site after encountering one, create a custom 404 error page that features links to your other content.
For example, if your 404 page features your most visited pages, visitors may see the information they were actually looking for and then follow that link. Check out this example to see how Drift uses its content to get people to stay on its website.
XML Sitemap
Once your website is ready to be launched, create your XML sitemap and submit it to Google Search Console.
An XML sitemap is a list of the URLs for the pages and files on your site you want search engines to crawl and the date when they were last modified. It serves as a way to help search engine bots better understand the scope of your site so they can crawl it and index it.
If you use a CMS like WordPress, you can have your XML sitemap generated automatically.
XML Sitemap Best Practices
- Use a dynamic sitemap if possible.
- Only include canonical pages and pages you want search engines to index in your sitemap.
- Exclude noindex pages (i.e., pages you don’t want Google and other search engines to return in search results).
- Keep your sitemap up-to-date. If you alter your website architecture or add or remove pages, modify your XML sitemap and resubmit it to Google Search Console.
Learn more about XML sitemaps and check out some examples here.
Crawling & Indexing
To show up as a result for appropriate queries, your web pages must first be crawled and indexed by search engine bots.
How Crawling & Indexing Work
Search engines have applications called “bots” or “search engine crawlers” that travel across links to find pages, “read” them, and add them to their database. Crawling is the term used to describe how these bots read the information on a web page, and indexing is the act of parsing and categorizing that information so that the search engine can return a web page for relevant search queries. If your pages aren’t crawled and indexed, they can’t show up in search results — which means no organic traffic.
Googlebot and Other Crawlers
There are over 1.7 billion websites. Imagine trying to read all of the pages on those websites and then create a directory that allows you to reference all those pages by topic.
Seems like a near-impossible feat for a human. Thankfully, this task is outsourced to search engine crawlers.
Search engine crawlers are software created by individual search engines that visit web pages, read them, and then index them. They are also called search bots, search crawlers, web crawlers, search engine spiders, and more. We tend to concern ourselves with Googlebot, which is the proprietary name for Google’s crawlers.
Because you need these bots to be able to crawl and understand your web pages so they can show up in search results, you’ll want to make it easier for them to identify which pages they should crawl, how your pages relate to each other, and what exactly your page is about. Your XML sitemap provides a roadmap to your indexable pages, but there are additional tools you can use to help search engines find what you want them to find.
Let’s jump into the tech SEO basics that affect how your website is crawled and indexed.
Robots.txt
Robots.txt allows you to specify whether search engine crawlers can index particular directories. It allows you to preserve your crawl budget and reduce the chance of index bloat. You can create a robots.txt that tells search engine crawlers not to index your WordPress login page, for example.
Your robotx.txt should be located on your root domain and should include the URL of your XML sitemap so search engines can find it easily.
If you don’t have one, easily generate one with Yoast.
Robots Meta Tags
While robots.txt allows you to give instructions for several pages or an entire site, a robots meta tag allows you to provide direction to search engine crawlers at the page level.
The robots meta tags, or noindex tag, can tell a specific search engine crawler, or all bots, to not crawl or index your page. Here’s a list of the possible directives you can use.
X-Robots
X-Robots lets you tell search engine crawlers how to handle non-HTML files. Block indexation of particular files or images by adding X-Robots to your .php or server configuration files.
Rel Canonical
Duplicate content can harm your SEO and make it harder for a particular page to rank well. When Google and other search engines find duplicate content, they make a choice regarding which is the original that should appear in search results.
For example, if you create an in-depth post about how great eco-friendly carpet cleaning is and share it on both your blog and your Medium account, Google will decide which to return in search results. To avoid this and indicate which page you want to show up in SERPs, specify which URL is the original using a canonical tag.
A canonical tag indicates which URL a search engine should treat as the original content source. It’s a simple piece of code that, when pasted into your <head>, directs search engines to index the appropriate URL. For example, if your ecommerce site has multiple product pages for “red shoes,” a canonical tag can help ensure that Google only indexes the first page of results.
Canonical tags can be self-referencing, which means you can use one on a page to identify it as the canonical page. We recommend each of your pages have a self-referencing canonical tag. Find our best practices for canonical tags here.
Index Bloat
Index bloat happens when search engines crawl and index pages that aren’t important or that you don’t want showing in search results. For example, if you have a search feature on your blog, it’ll generate a new URL for each search a visitor runs. If you fail to noindex these URLs, Googlebot will attempt to crawl and index them — wasting valuable time that could be better spent on your more high-profile pages.
Google and other search engines limit how many pages their bot crawls on your site per day. This number is your “crawl budget.” It’s not a set number. Rather, it’s determined by how big your site is, how healthy it is (i.e., how many errors it has), and how many backlinks you receive.
When your site suffers from index bloat, it also means your crawl budget is being unnecessarily wasted on unimportant pages. To avoid index bloat and preserve your crawl budget, make use of robot.txt, meta robot tags, and rel canonical tags to keep search engines from indexing unimportant sites and implement an internal linking strategy.
To manage index bloat, verify your robots.txt file is set up correctly. Use noindex meta tags to request pages be removed from your index.
Internal Links
Internal links not only make it easier for users to navigate your website, they also make it easier for search engines to crawl and index it.
By linking topically related content together, you make it obvious that those pages are related. This helps visitors find additional content that’s relevant to their initial query. Internal links can help you preserve your crawl budget and pass link equity from one page to another.
Internal Linking Strategy
Earlier, we covered site architecture. Your internal linking strategy should help make your site architecture more obvious. Let’s say you have a subdirectory on your website for your dog grooming service. Pages and blog posts that are topically relevant, like “How Often Should I Give My Dog a Bath” and “The Importance of Trimming Puppy Nails” should all link back to your dog grooming service page. You can also link those two posts together.
Learn how to create an internal linking strategy here.
Anchor Text
When linking, be sure to think about your anchor text. This is the text you’re actually using to link to another page. When linking internally, use the destination page’s keyword or a semantically related phrase as the anchor text as this helps both readers and Googlebot understand what the linked page is about.
Broken Links
In addition, you should regularly check for broken links on your site. Broken links impact user experience and can lead to URLs returning 404 errors being removed from Google’s index.
Check out this article to learn how to find and fix broken links.
Structured Data Markup (Schema)
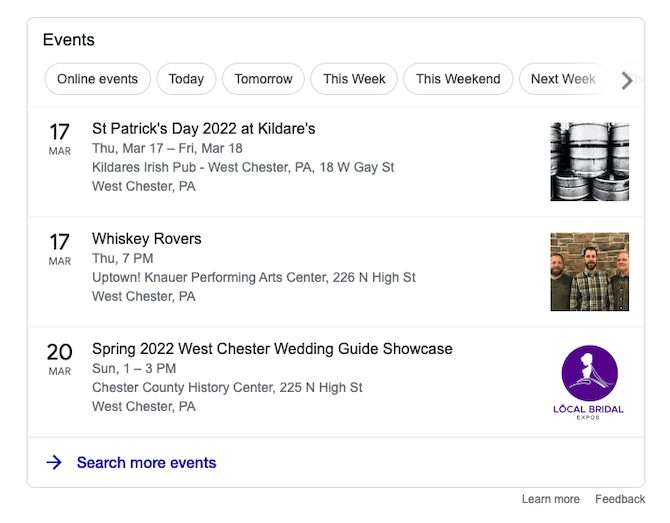
Structured data is standardized code that allows you to share more information about a page or content with search engine bots so they can better understand it. Using structured data for particular types of content can increase its chances of showing up in rich snippet results. For example, if you have an upcoming event, use schema to note the name of your event, when it’s happening, and where it’s taking place. If someone were to search for events nearby, yours might appear in Google’s rich results at the top of search results.
Structured data does not show up visually on your page — only in your code. So while search engine bots can use it to gather useful information, it doesn’t impact how your page looks to web visitors.
At Victorious, we recommend using JSON-LD, which is Google’s preferred schema markup language. Use it on product pages, FAQ pages, recipe pages, and more.
Check out this easy tutorial for implementing schema markup on your website and learn how to read your Google Search Console Structured Data report here.
Redirects
Redirects transfer a web visitor from one page to another, often without them even noticing. There are multiple types of redirects, but the primary two you need to know are 301 redirects and 302 redirects.
301 redirects are permanent redirects. They tell a search engine crawler the new URL is the one they should index and that they should pass link equity from the redirected URL to the new destination URL. You should use this redirect when you change a page’s URL, delete a URL, or merge pages. It’ll help pass PageRank and transfer link equity from backlinks to the new URL.
302 redirects are temporary redirects. They tell crawlers they should continue to index the original URL but that, for right now, the new URL has the information the searcher is looking for. These types of redirects should only be used in the short term, like if you’re hosting a sale or have an event page you’d like to redirect searchers to. Because these redirects are seen as temporary, link equity is not passed.
In 2021, John Mueller was quoted as saying, “with redirects, we tend to put URLs into the same bucket, and then use canonicalization to pick which one to show.” If you want a particular URL to be considered canonical when using a 302 redirect, be sure to use the rel canonical tag.
Page Experience Signals
In 2021, Google rolled out the Page Experience update and created a new report in Google Search Console to make it easier for website owners to see how well their website performs on their UX measure.
The page experience update combined core web vitals with other ranking factors that Google monitors, like mobile-friendliness, the use of HTTPS (which I mentioned above), and intrusive interstitials.
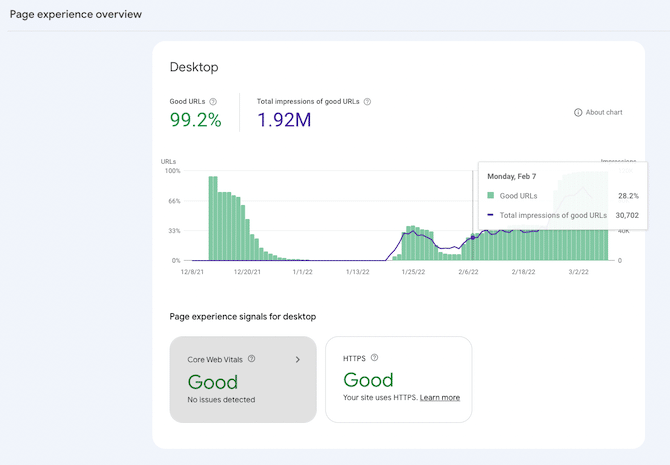
Regularly checking your Page Experience report will allow you to identify and remedy potential issues. Let’s talk about the most important aspects of the Page Experience Signals.
Core Web Vitals
Core web vitals provide insight into how users are able to interact with your website. Google has chosen three variables to indicate how quickly a web page becomes functional: large contentful paint, first input delay, and cumulative layout shift.
Largest Contentful Paint
Largest contentful paint (LCP) is the measure Google uses to determine how quickly a page loads. It’s the point at which enough of the content on a page has loaded and the page becomes useful to a visitor.
Page load speed is crucial for UX. Visitors bounce if a page takes too long to load. By decreasing your LCP, you get your information in front of users faster and hopefully get them to stay on your site longer.
First contentful paint (FCP) is not part of Google’s Page Experience Signals, but it can be a useful measure of perceived page load speed. FCP marks when the first item on a page is rendered visible to a visitor.
First Input Delay
Google uses first input delay (FID) to determine the interactivity of a web page. It focuses on how long it takes a site to register and respond to a user action. For example, if a visitor clicks “buy now” on your website, the FID would be how long it takes for your checkout page or “item added to cart” pop-up to load. Ideally, your FID should be under 100ms.
Cumulative Layout Shift
Cumulative layout shift (CLS) is the measure Google uses to determine the visual stability of a web page. It captures whether content moves on the site while it’s rendering. For example, if different components of a page load at different times, they may cause other components, like text or images, to shift. This can make it harder for a visitor to begin using a site. Cumulative layout shift measures how much of a page is affected by these types of layout shifts.
Some layout shifts are expected — like those that occur because of a user action like clicking a button. However, others can negatively impact user experience. The latter shifts are the ones you’ll want to reduce.
Google has a helpful video about CLS and how to improve it.
You can view the FCP, LCP, FID, and CLS of a particular page using Google’s PageSpeed Insights.
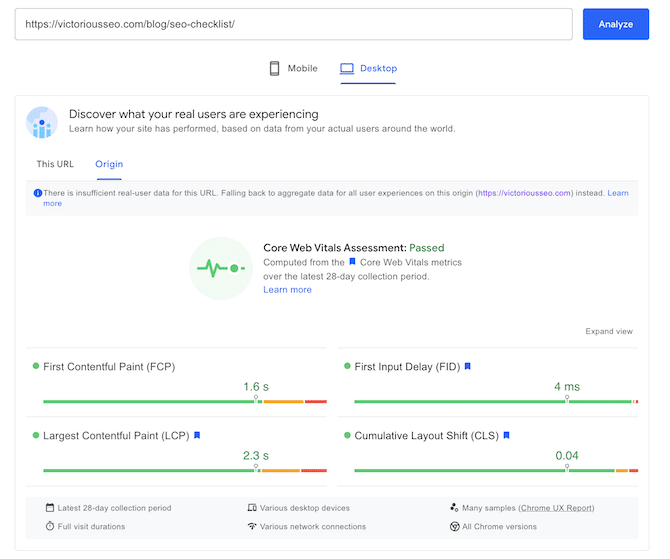
Learn more about Google PageSpeed Insights and Lighthouse here.
Mobile Friendliness
Whether or not this comes as a surprise will depend on your preferred device, but as of Q4 2021, 63% of searches happen on a mobile device.
It’s no wonder, then, that Google and other search engines care about how well your website performs on mobile. They want to provide searchers with the best possible suggestions for their queries — and that includes the UX of the web pages they return in results.
If your website looks great on a desktop but has functionality or usability issues on mobile, search engines may not rank it as highly in search results.
To make your website mobile-friendly, optimize your images, ensure your fonts translate well to a mobile interface, check your links are visible and clickable, and more.
For more tips, check out our best practices for mobile friendliness.
Interstitials
In SEO, pop-ups and banners are also called “interstitials.” As part of their Page Experience update, Google looks for intrusive interstitials that they believe have a negative impact on the UX of a web page.
So what’s the difference between a regular (or even necessary) interstitial and an intrusive one?
If you visit a web page for a liquor brand or a cannabis dispensary, you’ll be greeted by an age gate. This is considered a necessary interstitial and won’t harm page experience. The same goes for pop-ups about cookies.
On the other hand, if you go to a retail site and a huge pop-up shows up asking you to sign up for their newsletter or offering a special deal, this can be viewed as an intrusive interstitial.
Intrusive interstitials cover most of the content on the page and interrupt the browsing experience. This is often more obvious on mobile — especially if the pop-up isn’t responsive and fails to close.
Google does a great job of explaining intrusive interstitials and showing what is acceptable in this article on improving the mobile experience.
Technical SEO Tools
Google Search Console
Google Search Console (GSC) is a valuable tool for a website owner. At Victorious, we recommend our clients verify their sites on GSC.
GSC allows you to see how your website is performing in Google search. Check your page experience signals, identify which pages Google has crawled, request indexing, see who’s linking to your site, and discover your top pages.
GSC helps you monitor how well your SEO strategy is working so you can continue to improve your site. Check out our Guide to Google Search Console to learn more.
Google Analytics
Google Analytics (GA) is a free web analytics tool from the world’s most popular search engine. Get deeper insights into how many people visit your website, the search terms people use to find you, and what people do when they get to your site with GA.
GA essentially allows you to monitor the effectiveness of your SEO strategy. Verify optimizations and content production are drawing additional visitors or uncover underperforming pages.
Check out our starter guide for Google Analytics to learn how to set up your account and learn our top tips for getting the most from your account. Then learn how to measure traffic.
To maximize the value of your GA account, create and track events. While there are plenty of potential things to track, make sure they align with your broader SEO goals so you can stay on target. For example, track how many people downloaded your lead magnet or signed up for a free demo of your product.
Page Speed Insights
Check how quickly a web page loads on mobile or desktop with Google’s PageSpeed Insights tool. Input your URL and hit “Analyze” to learn more about how well your page’s core web vitals perform.
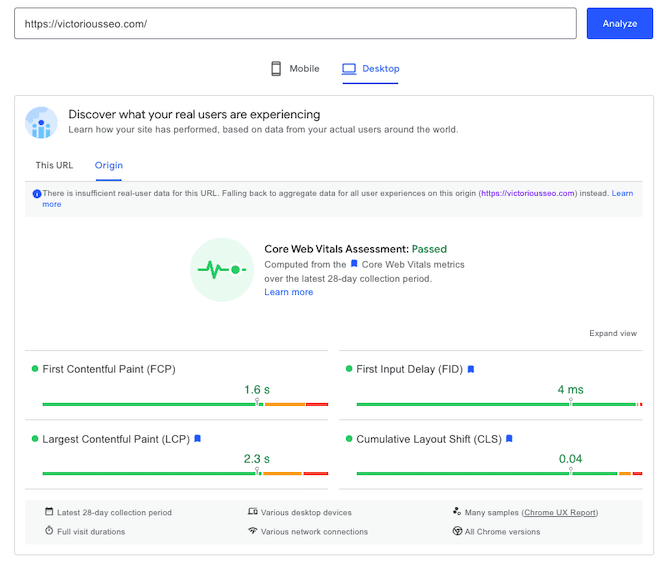
Similar information can be found in GSC for your entire site. Check under “Experience” on the left-hand sidebar where it says “Core Web Vitals.”
Mobile-Friendly Test
Verify a web page works well on a variety of devices with Google’s mobile-friendly test. Input your URL into this free tool, and Google will crawl your page.
You can use GSC to check if your entire site is mobile-friendly. You’ll find “Mobile Usability” under “Experience” on the left-hand sidebar.
Partner with an SEO Agency for Tech SEO Expertise
This is a lot to take in — technical SEO encompasses many moving pieces. However, because it can greatly impact the user experience and how visitors interact with your brand, it’s a critical part of a comprehensive SEO strategy.
If you partner with an SEO agency, you can rest assured that technical barriers won’t block qualified organic traffic from finding your site. Whether you’re looking for more organic traffic, higher conversion rates, or greater brand awareness, Victorious has the tools to support your business.
Learn more about what a technical SEO audit can reveal about your website. Schedule a free consultation today.



