
Explaining SEO to people can be hard because there are a lot of little steps that might not seem very important at first, yet they add up to big gains in search rankings when done right.
One important step that is easy to overlook is letting search engine crawlers know which pages to index — and which not to. You can do this with a robots.txt file.
In today’s post, I’m going to explain exactly how to create a robots.txt file so you can get this foundational part of your site squared away and make sure crawlers are interacting with your site in the way you want.
What Is a robots.txt File?
The robots.txt file is a simple directive that tells search engine crawlers which pages on your site to crawl and index.
It’s part of the robots exclusion protocol (REP), a family of standard procedures that govern how search engine robots crawl the web, assess and index site content, and then serve that content up to users. This file specifies where crawlers are allowed to crawl and where they are not allowed to. It can also contain information that could help crawlers more efficiently crawl the website.
The REP also includes “meta robots tags,” which are directives included in a page’s HTML that contain specific instructions on how web crawlers should crawl and index particular web pages and the images or files they contain.
What’s the Difference Between Robots.txt and Meta Robots Tag?
As I mentioned, the robots exclusion protocol also includes “meta robots tags,” which are pieces of code included in a page’s HTML. They’re different from robots.txt files in that they provide direction to web crawlers on specific web pages, disallowing access either to the complete page or to particular files contained on the page, such as photos and videos.
In contrast, robots.txt files are intended to keep whole segments of a website from being indexed, such as a subdirectory only intended for internal use. A robots.txt file lives on your site’s root domain rather than on a particular page, and the directives are structured such that they affect all pages contained within the directories or subdirectories they refer to.
Why Do I Need a Robots.txt File?
The robots.txt file is a deceptively simple text file of great importance. Without it, web crawlers will simply index every single page they find.
Why does this matter?
For starters, crawling an entire site takes time and resources. All that costs money, so Google limits how much it will crawl a site, especially if that site is very big. This is known as “crawl budget.” Crawl budget is limited by several technical factors, including response time, low-value URLs, and the number of errors encountered.
Plus, if you allow search engines unfettered access to all of your pages and let their crawlers index them, you may end up with index bloat. This means Google may rank unimportant pages you don’t want to appear in search results. These results could provide visitors with a poor experience, and they could even end up competing with pages you want to rank for.
When you add a robots.txt file to your site or update your existing file, you can reduce crawl budget waste and limit index bloat.
Where Can I Find My Robots.txt File?
There’s a simple way to see if your site has a robots.txt file: Look it up on the internet.
Just type in the URL of any site and add “/robots.txt” to the end. For instance: victorious.com/robots.txt shows you ours.
Try it yourself by typing in your site URL and adding “/robots.txt” to the end. You should see one of three things:
- A couple of lines of text indicating a valid robots.txt file
- A completely blank page, indicating there’s no actual robots.txt file
- A 404 error
If you’re checking your site and getting either of the second two results, you’ll want to create a robots.txt file to help search engines better understand where they should focus their efforts.
How To Create a Robots.txt File
A robots.txt file includes certain commands that search engine robots can read and follow. Here are some of the terms you’ll use when you create a robots.txt file.
Common Robots.txt Terms to Know
User-Agent: A user-agent is any piece of software tasked with retrieving and presenting web content for end-users. While web browsers, media players, and plug-ins can all be considered examples of user-agents, in the context of robot.txt files, a user-agent is a search engine crawler or spider (such as Googlebot) that crawls and indexes your website.
Allow: When contained in a robots.txt file, this command permits user-agents to crawl any pages that follow it. For example, if the command reads “Allow: /” this means any web crawler can access any page that follows the slash in “https://www.example.com/.” You don’t need to add this for everything you want crawled, as anything not disallowed by the robots.txt is implicitly allowed. Instead, use it to allow access to a subdirectory that is in a disallowed path. For example, WordPress sites often have a disallow directive for the /wp-admin/ folder, which in turn requires them to add an allow directive to allow crawlers to reach /wp-admin/admin-ajax.php without reaching anything else in the main folder.
Disallow: This command prohibits specific user-agents from crawling the pages that follow the specified folder. For example, if the command reads “Disallow: /blog/” this means the user agent may not crawl any URLs that contain the /blog/ subdirectory, which would exclude the whole blog from search. You would probably never want to do that, but you could. That’s why it’s very important to consider the implications of using the disallow directive any time you think about making changes to your robots.txt file.
Crawl-delay: While this command is regarded as unofficial, it’s designed to keep web crawlers from potentially overwhelming servers with requests. It’s typically implemented on websites where too many requests could cause server issues. Some search engines support it, but Google does not. You can adjust crawl rate for Google by opening Google Search Console, navigating to your property’s Crawl Rate Settings page, and adjusting the slider there. This only works if Google thinks it is not optimal. If you think it is suboptimal and Google disagrees, you may need to put in a special request to get it adjusted. That’s because Google prefers you allow them to optimize the crawl rate for your website.
XML Sitemap: This directive does exactly what you’d guess it does: tell web crawlers where your XML sitemap is. It should look something like: “Sitemap: https://www.example.com/sitemap.xml.” You can learn more about sitemap best practices here.
Learn more about robots.txt syntax here.
Step-by-Step Instructions for Creating Robots.txt
To create your own robots.txt file, you’ll need access to a simple text editor such as Notepad or TextEdit. It’s important not to use a word processor, as these typically save files in proprietary forms and may add special characters to the file.
For simplicity’s sake, we’ll use “www.example.com.”
We’ll begin by setting the user-agent parameters. On the first line, type:
User-agent: *
The asterisk means all web crawlers are permitted to visit your website.
Some websites will use an allow directive to say that bots are allowed to crawl, but this is unnecessary. Any parts of the site that you have not disallowed are implicitly allowed.
Next, we’ll enter the disallow parameter if needed. Hit “return” twice to insert a break after the user-agent line, then type the disallow parameter followed by the directory you don’t want crawled. Here’s what ours looks like:
Disallow: /wp/wp-admin/
Disallow: /*?*
The first command ensures our WordPress admin pages (where we edit stuff like this article) aren’t crawled. These are pages we don’t want ranking in search, and it would be a waste of Google’s time to crawl them because they’re password protected. The second command prevents search bots from crawling URLs that contain a question mark, like internal blog search results pages.
Once you’ve completed your commands, link to your sitemap. While this step isn’t technically required, it’s a recommended best practice since it points web spiders to the most important pages on your site and makes your site architecture clear. After inserting another line break, type:
Sitemap: https://www.example.com/sitemap.xml
Now your web developer can upload your file to your website.
Creating a Robots.txt file in WordPress
If you have Admin access to your WordPress, you can modify your robots.txt file with the Yoast SEO Plugin or AIOSEO. Alternatively, your web developer can use an FTP or SFTP client to connect to your WordPress site and access the root directory.
Do not move the robots.txt file anywhere other than the root directory. While some sources suggest placing it in a subdirectory or subdomain, ideally, it should live on your root domain: www.example.com/robots.txt.
How To Test Your Robots.txt File
Now that you’ve created a robots.txt file, it’s time to test it out. Fortunately, Google makes it easy by providing a robots.txt Tester as part of Google Search Console.
After you open the tester for your site, you’ll see any syntax warnings and logic errors highlighted.
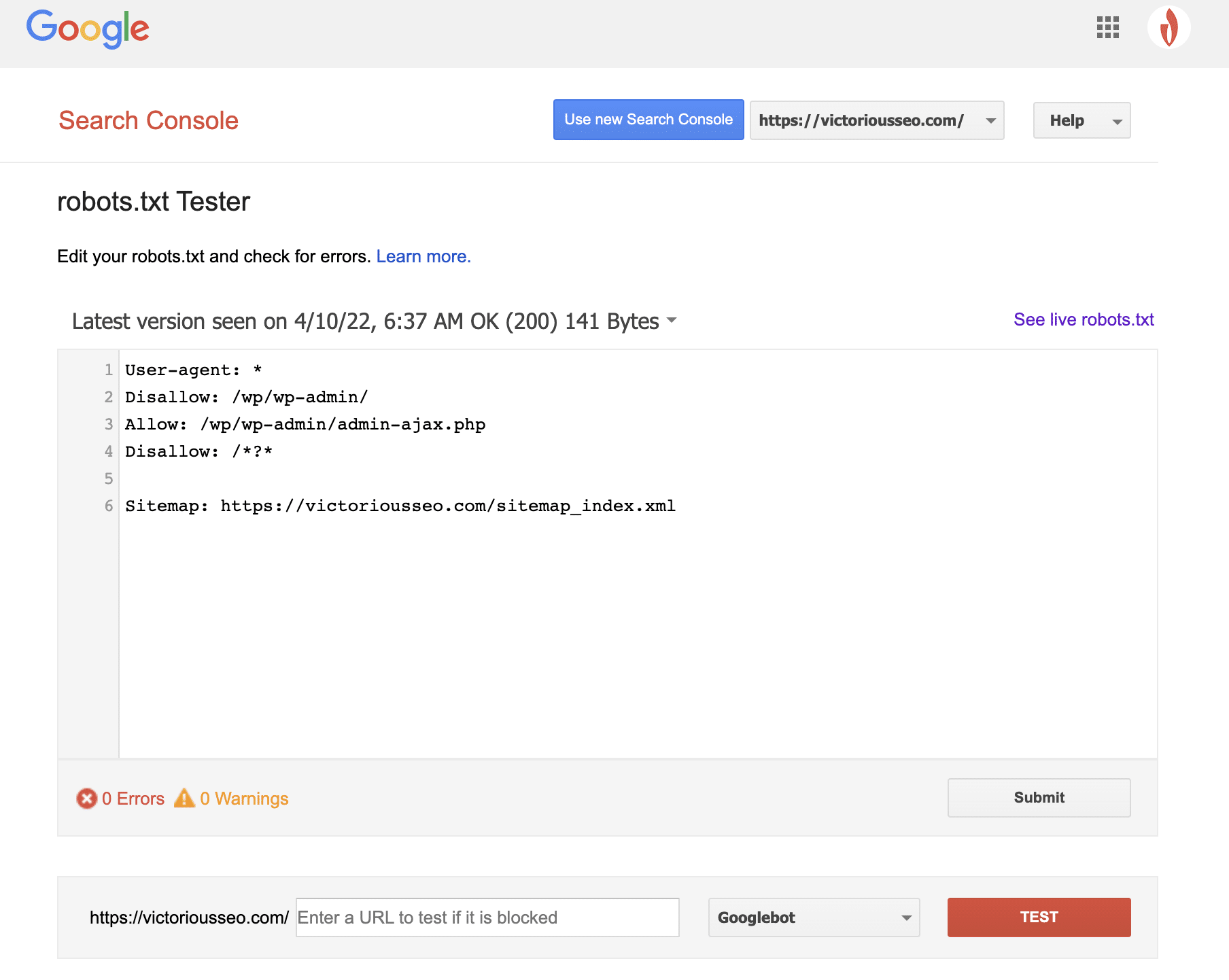
To test how a particular Googlebot “sees” your page, enter a URL from your site in the text box at the bottom of the page and then choose from among the various Googlebots in the dropdown to the right. Hitting “TEST” will simulate the behavior of the bot you selected and show if any directives are preventing Googlebot from accessing the page.

Robots.txt’s Shortcomings
Robots.txt files are very useful, but they do have their limitations.
Robots.txt files should not be used to protect or hide parts of your website (doing so could violate the Data Protection Act). Remember when I suggested you search for your own robots.txt file? That means anyone can access it, not just you. If there’s information you need to protect, the best approach is to password-protect specific pages or documents.
In addition, your robots.txt file directives are simply requests. You can expect Googlebot and other legitimate crawlers to obey your directives, but other bots may simply ignore them.
Finally, even if you request crawlers not index specific URLs, they’re not invisible. Other websites may link to them. If you don’t want certain information on your website available for public viewing, you should password-protect it. If you want to make certain that it will not be indexed, consider including a noindex tag on the page.
Learn More About Technical SEO: Download Our Checklist
Want to learn more about SEO, including step-by-step instructions on how to take your website’s SEO into your own hands? Download our SEO Checklist to get a comprehensive to-do list, including valuable resources that will help you improve your search rankings and drive more organic traffic to your website.

2025 SEO Checklist
Ready to move the needle on your SEO? Download our interactive checklists and
start improving your site today.


