
Bottom line: If Google isn’t able to crawl your important pages, they won’t show up in search results. This could lead to lower-than-expected organic traffic and depressed rankings.
Crawl budget optimization makes it easier for Google to access, crawl, and index each of your important pages so you can reach more customers via search. Here’s what you need to know about crawl budget, how to identify crawl budget waste, and what you can do to optimize your site to avoid any possible SEO crawl budget problems.
What Is Crawl Budget?
Your crawl budget refers to the number of your site’s pages that Google crawls on any given day. It’s based on your crawl rate limit and crawl demand.
Your crawl rate limit is the number of pages Google can crawl without affecting the user experience of your website. Essentially, Google doesn’t want to overload your server with requests, so it finds a happy medium between what your server can handle (your server resources) and how much it “wants” to crawl your site.
Your crawl demand is determined by how popular a URL is and its freshness. If a URL is stale and few people are searching for it, Google will crawl it less frequently.
While you can’t impact your crawl rate, you can impact your crawl demand by creating fresh content, optimizing your site with SEO best practices, and tackling SEO issues like 404s and unnecessary redirects.
What Is Crawl Budget Optimization?
Crawl budget optimization is the process of making your site easier for Googlebot to access, crawl, and index by improving search crawler navigability and reducing crawl budget waste. This includes reducing errors and broken links, improving internal linking, noindexing duplicate content, and more.
Crawl budget can become an issue when Google isn’t crawling enough of the pages on your site or isn’t crawling them frequently enough.
Because it only has a certain number of resources to work with, Google can only allot so many crawls to any given site on any given day. If you have a large site, this means Google may only have the resources to crawl a small fraction of your site’s pages daily. This can impact how long it takes for your pages to be indexed or for content updates to be reflected in Google rankings.
Thankfully, if you think your site may be suffering from Google crawl budget problems, there are certain things you can do to optimize your site and make the most of your crawl budget.
How To Check Your Crawl Stats Report
You can identify crawl budget problems by checking your crawl stats in Google Search Console or by analyzing your server file logs.
Viewing your crawl stats report in Google Search Console can help you better understand how Googlebot is interacting with your website. Here’s how you can use it to see what Google’s crawler has been up to.
Open up Google Search Console, log in, and choose your website. Then select the ‘Settings’ option from the Search Console menu.
You can see your crawl report for the last 90 days under the crawl stats section. Open it up by clicking on ‘Open Report.’
What Your Crawl Stat Report Means
Now that you can see Googlebot’s activity, it’s time to decode the data. Here’s a quick breakdown of the kind of information you can get from your crawl report.
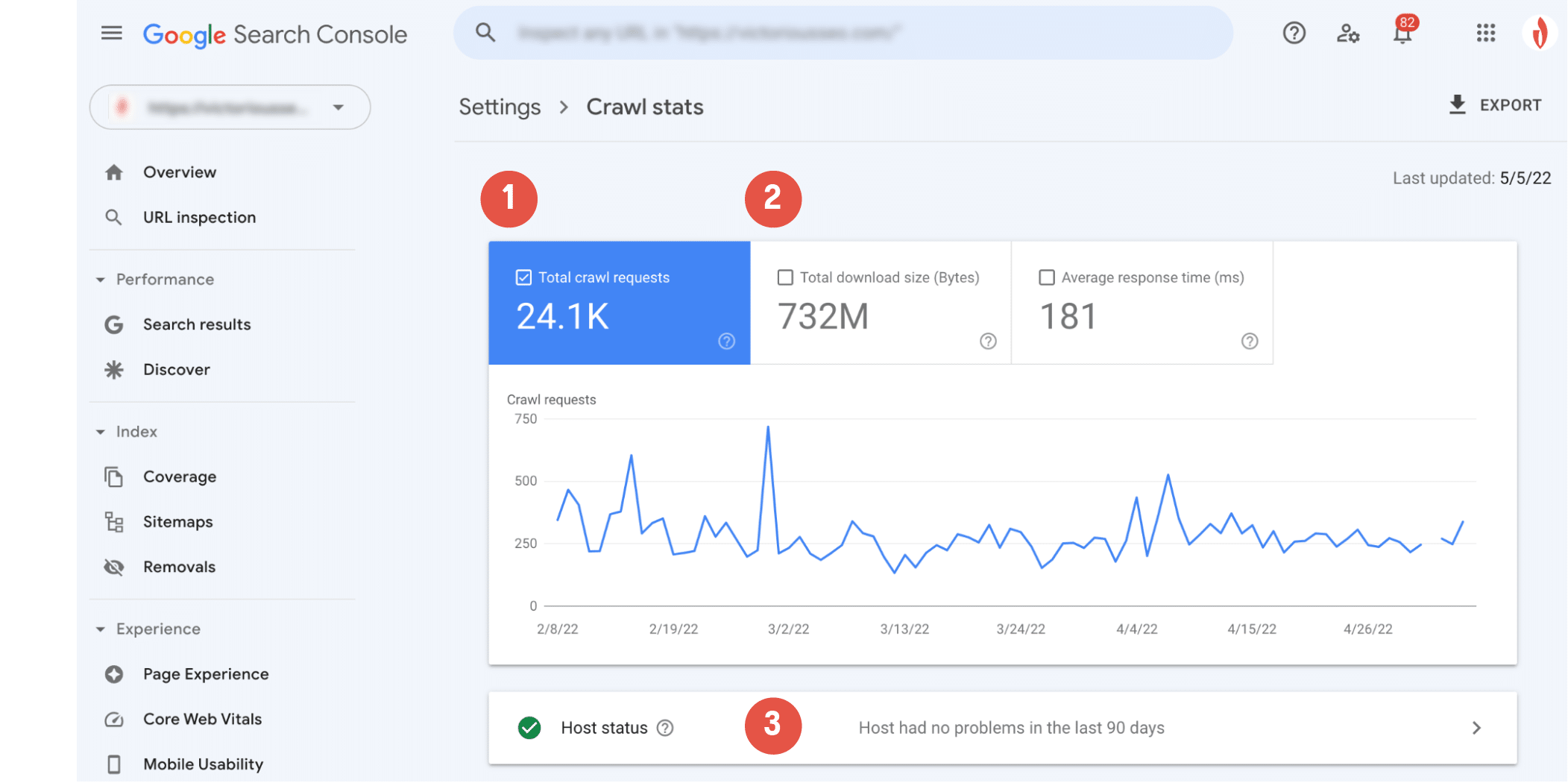
The main crawl chart will show you a visual representation of Googlebot’s crawling activity. Here you can see (1) how many crawl requests Google has put in over the last 90 days and (2) the average response time of your site’s server and the total amount of bytes downloaded while crawling.
The ‘Host status’ section (3) will let you know if the crawler encountered any availability problems while accessing your website.
A green circle with a white checkmark means that Googlebot encountered no problems and indicates that your host is running smoothly.
A white circle with a green checkmark means Googlebot encountered an issue over a week ago, but everything is running fine now.
A red circle with a white exclamation point indicates Googlebot has encountered at least one significant issue within the past week.
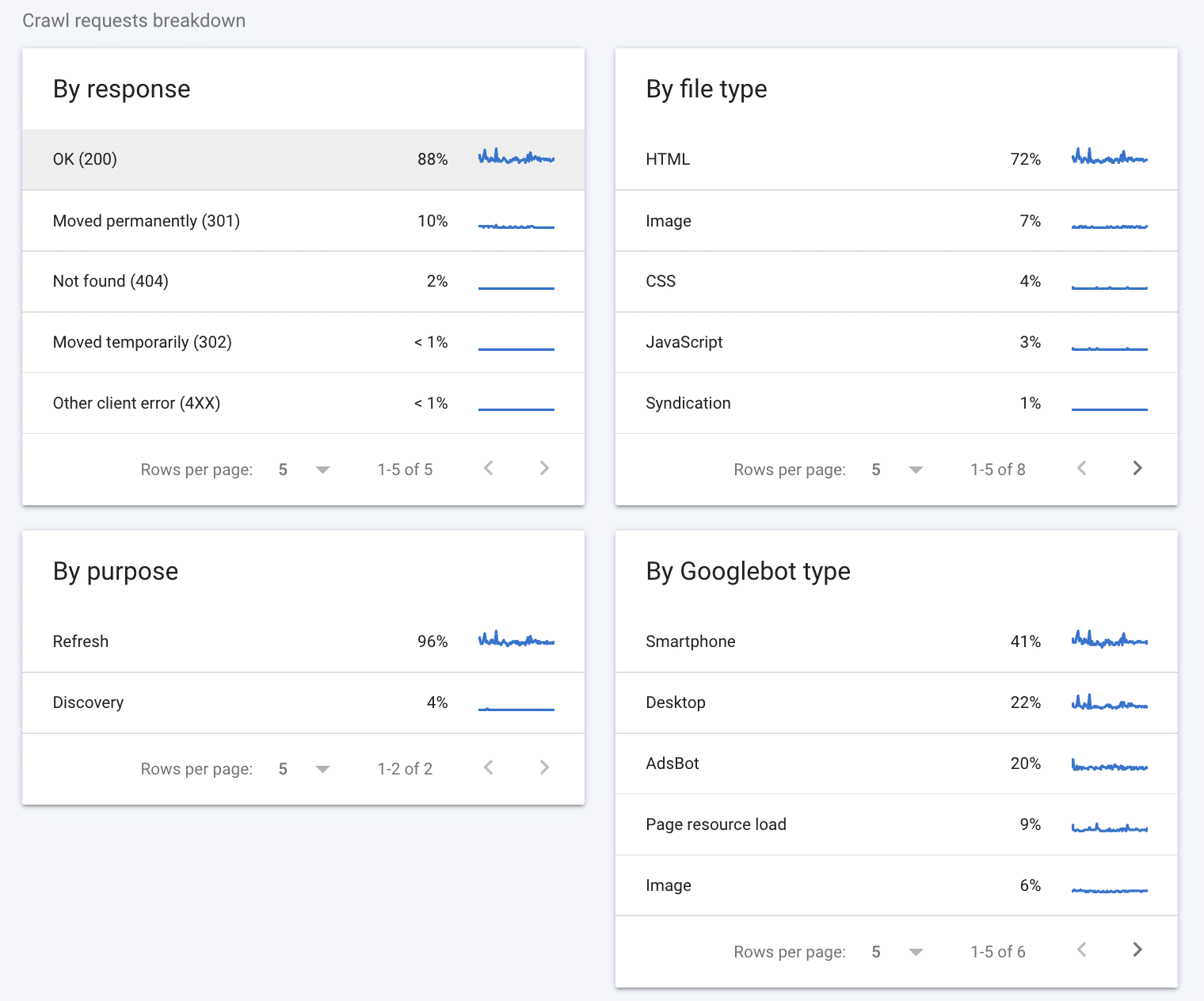
The crawl requests breakdown provides some more detailed information about how Google’s crawlers have been interacting with your site.
By Response
The first section to look at is the ‘By response’ section. This section tells you what kind of responses Googlebot received when attempting to crawl the pages on your site. Google considers the following to be good responses:
- OK (200)
- Moved permanently (301)
- Moved temporarily (302)
- Moved (other)
- Not modified (304)
Ideally, the majority of responses should be 200 (some 301s are ok, too). Codes like ‘Not found (404)’ are a heads up that there are likely dead ends on your website possibly affecting your crawl budget.
File Type
The ‘By file type’ section tells you what type of file Googlebot encountered during the crawl. The percentage values you see are representative of the percentage of responses of that type and not of the percentage of bytes of each file type.
By Purpose
The ‘By purpose’ section indicates whether the page crawled was one the crawler has seen before (a refresh) or one that is new to the crawler (a discovery).
By Googlebot Type
Lastly, the ‘By Googlebot type’ section tells you about the types of Googlebot crawling agents used to make requests and crawl your site. For example, the ‘Smartphone’ type indicates a visit by Google’s smartphone crawler, while the ‘AdsBot’ type indicates a crawl by one of Google’s AdsBot crawlers. As a side note, you can always disable specific types of Googlebots from crawling your website by editing the robots.txt file.
Check out Google’s guide to Search Console crawl reports if you want to learn more about how to interpret the data in your crawl report.
How To Tell If You’re Wasting Your Crawl Budget
A quick way to determine whether optimizing crawl budget will help Googlebot crawl more of your pages is by seeing what percentage of your site’s pages are actually being crawled per day.
Find out exactly how many unique pages you have on your website and divide it by the “average crawled per day” number. If you have ten or more times the amount of total pages than pages crawled per day, you should consider crawl budget optimization.
If you think you’re having crawl issues, then start by looking at the ‘By response’ section to see what kinds of errors the crawler may be running into. You’ll likely need to perform a deeper analysis to see exactly what’s eating away at your budget. A look at your server logs can give you more information about how the crawler is interacting with your site.
Check Your Server Logs
Another way to check if you’re wasting crawl budget is to look at your site’s server logs. These logs store every single request made to your website, including the requests Googlebot makes when it crawls your site. Analyzing your server logs can tell you how often Google crawls your website, which pages the crawler is accessing most often, and what type of errors the crawler bot encountered.
You can check these logs manually, although digging for this data can be a bit tedious. Thankfully, several different log analyzer tools can help you sort and make sense of your log data, like the SEMRush log file analyzer or Screaming Frog SEO log file analyzer.
Crawl Budget SEO: 8 Ways To Optimize Your Crawl Budget
Did you uncover wasted crawl budget? Crawl budget SEO optimization strategies can help you curb waste. Here are eight tips to help you optimize your SEO crawl budget for better performance.
1. Finetune Robots.txt & Robots Meta Tags
One way to curb wasted crawl budget is to prevent Google’s crawler from crawling certain pages in the first place. By keeping Googlebot away from pages you don’t want indexed, you can focus its attention on your more important pages.
The robots.txt file sets boundaries for search crawlers declaring which pages you want crawled and which are off-limits. Adding a disallow command into your robots.txt file will block crawlers from accessing, crawling, and indexing the specified subdirectories unless there are links pointing to those pages.
At the page level, you can use robots meta tags to noindex particular pages. A noindex tag allows Googlebot to access your page and follow its links on it, but it tells Googlebot to refrain from indexing the page itself. This tag goes directly into the <head> element of your HTML code and looks like this:
<meta name=”robots” content=”noindex” />2. Prune Content
Hosting low-value URLs or duplicate content on your site can be a drag on your crawl budget. A deep dive through your website’s pages can help you to identify unnecessary pages which may eat up crawl budget and prevent more valuable content from being crawled and indexed.
What qualifies as being a low-value URL? According to Google, low-value URLs typically fall into one of several categories:
- Duplicate content
- Session identifiers
- Soft error pages
- Hacked pages
- Low quality & spam content
Duplicate content isn’t always easy to identify. If most of the content on a page is the same as that of another page — even if you’ve added more content or changes some words — Google will view it as appreciably similar. Make use of noindex meta tags and canonical tags to indicate which page is the original that should be indexed.
By updating, removing, or noindexing content that may register as low-value, you give Googlebot more opportunities to crawl the pages on your site that are truly important.
3. Remove or Render JavaScript
Googlebot has no problem reading HTML, however, it has to render JavaScript before it can read it and index it. So rather than crawling and indexing a JavaScript element on a page, Google crawls the HTML content on the page and then places the page in a render queue. When it has the time and resources to devote to rendering, it will render the JavaScript and “read” it, then finally index it. This extra step doesn’t just take more time — it takes more crawl budget.
JavaScript can also affect your page load times, and since site speed and server load impact your crawl budget, Google may crawl your site less frequently than you would like if it’s bogged down with too much JavaScript.
To conserve crawl budget, you can noindex pages with JavaScript, remove your JavaScript elements, or implement static or server-side rendering to make it easier for Google to understand and crawl. Learn more about JavaScript SEO here.
4. Remove 301 Redirect Chains
301 redirects are a useful and SEO-friendly way of transferring traffic and link equity from a URL you want to remove to another relevant URL.
However, it’s easy to accidentally create redirect chains if you aren’t tracking your redirects. Not only can this lead to increased load times for your site’s visitors, but it can also cause crawlers to crawl multiple URLs just to access one page of actual content. That means Google will need to crawl every URL in the redirect chain to get to the destination page, eating up your crawl budget in the process.
To prevent this, make sure all your redirects point to their final destination. It’s always good practice to avoid using redirect chains whenever possible. Still, mistakes happen, so take some time to go through your site manually or use a redirect checking tool to spot and clean up any 301 redirect chains.
5. Follow XML Sitemap Best Practices
Your sitemap shares all of your important pages with search crawlers — or at least it should. Search engines crawl sitemaps to easily find pages. While Google says it doesn’t need one to find your pages, it’s still a good idea to maintain one.
To function well, your sitemap should only include pages you want indexed. You should remove any noindexed or redirected URLs from your sitemap. An easy way to do this is with a dynamically generated XML sitemap. Dynamically generated sitemaps update themselves, so you don’t have to worry about editing yours after every 301 you implement.
If you have multiple subdirectories on your site, use a sitemap index that houses links to each of your subdirectories’ sitemaps. This helps showcase your website architecture and provides an easy roadmap for search crawlers to follow.
6. Create An Internal Linking Strategy
Internal links don’t just help site visitors get around; they also create a clearer path of movement for crawler bots.
A well-developed internal linking strategy can point crawlers towards the pages you want crawled. Because crawlers use links to find other pages, interlinking deeper pages with higher-level content can help the crawler to access them more quickly. At the same time, removing links from low-priority pages that you don’t want eating into your crawl budget may help to push them to the back of the queue and ensure that your important pages get crawled first.
7. Fix Site Errors
Site errors can trip up search crawlers and waste valuable crawl budget. Ideally, you want the crawler to either encounter an actual page or a single redirect to that page. If it’s running into redirect chains or a 404 error page, then you’re wasting crawl budget.
Use your Google Search Console crawl report to identify where the crawler is running into errors and what kinds of errors they are. Ironing out any identifiable errors will create a smoother crawling experience for Googlebot.
8. Check For Broken Links
A URL is basically a bridge between two pages. It provides search engine crawler a pathway for finding new pages — but some URLs go nowhere. A broken link is a dead end for search engine crawlers and a waste of your limited crawl budget.
Take some time to check your site for broken links that may be sending search crawlers to dead pages and correct or remove them. In addition to reducing crawl budget waste, you’ll also be improving the visitor browsing experience by removing broken links, so doing a periodic link check is always a good idea.
Stop Wasted Crawl Budget With an SEO Audit
Feeling overwhelmed or unsure of where to start with optimizing your site’s crawl budget or general SEO? There’s no need to go it alone — our SEO and web maintenance services can help! Book a consultation with Victorious today and let our SEO and web dev experts help you through the process of performing an SEO audit and devising a strategy for optimizing your site’s SEO and technical performance.



