
Duplicate content can impact which of your pages shows up in search results and squander your crawl budget. Luckily, there are ways to identify duplicate content and either remove it from your website or Google’s index to prevent it from negatively affecting your ability to rank.
What Is Duplicate Content?
Duplicate content happens when the same content appears in more than one location with a unique URL.
Content doesn’t need to be an exact match to register as being duplicate — it can also be what Google calls “appreciably similar.” This content is essentially “close enough” to be considered duplicate content even though some text may differ.
Most site owners work hard to make sure their content is fresh and original, and yet there’s still plenty of duplicate content on the web. Sometimes site owners aren’t even aware of it. So how does this happen?
Why Does Duplicate Content Happen?
Most duplicate content on the web occurs due to the indexation of things like print-friendly versions of pages, products that are on or are linked to by several different URLs, and discussion forums that generate desktop and stripped-down mobile versions of the same page.
But those aren’t the only ways you can end up with duplicate content on your site. Here are some more examples of how duplicate content can happen internally on your site and externally on other sites.
Internally Generated Duplicates
Appreciably Similar Product Pages
Sometimes it can make sense to intentionally create appreciably similar pages, especially in e-commerce. For example, suppose you sell the same product in two different countries. In that case, you may choose to have two nearly identical pages, except one might display the price in US dollars while the other displays it in Canadian dollars.
Another example is product pages that appear appreciably similar because they feature the same copy, with the only real differences being a different product picture, product name, and product price.
Content Management Systems
Sometimes content management systems create duplicate content you might not even be aware of. Some systems add tags and URL parameters for searches automatically, resulting in multiple paths to the exact same content.
URL Variations
You can also end up with duplicate content if you have different URL variations that feature the same content. As previously mentioned, content management systems may do this on their own, and you may end up with two URL variations like https://www.website.com/blog1 and https://www.website.com/blogs/blog1. Other URL variations like trailing slashes or capitalized URLs can cause the same problem.
When this happens, Google may not know which page to rank and some outside sources may link to one of these pages while others link to the duplicate, breaking up your page’s link equity in the process.
HTTP vs HTTPS and www vs non-www
Most websites are accessible with or without www or at both HTTP or HTTPS URLs. However, if you haven’t configured your site correctly, Google may index pages from more than one of them, resulting in duplicate content.
Printer-Friendly and Mobile-Friendly URLs
Printer-friendly or mobile-friendly pages hosted at different URLs than the original page will result in duplicate content unless they’re properly noindexed.
Session IDs
Session IDs can be valuable tools to keep track of visitors checking out your site. This is generally done by adding a long session ID string to the URL. Because each session ID is unique, this creates a new URL and duplicates your content.
UTM Parameters
Parameters can track incoming visitors from various sources. Like Session IDs, they generate unique URLs although the content of the page is the same, thus creating duplicate content if indexed.
Externally Generated Duplicates
Syndicated Content
Syndicating your content to other sites on the web can be a great way to drive more traffic to your website and get your name out there. However, this content can still show up as duplicate content if not formatted with the proper canonical header tags. For example, using canonical tags on Medium articles can protect your original content from registering as a duplicate.
Plagiarism
While most duplicate content is non-malicious in nature, some website owners do copy content deliberately, seeking to benefit from content they didn’t produce themselves.
Duplicate Content SEO: Why Does It Matter?
If duplicate content happens so frequently, why does it matter? Here are five ways it can impact your ability to rank well in search results.
1. Google Duplicate Content Penalty
Google doesn’t directly penalize duplicate content — most of the time. If Google believes the duplicate content on your site is “deceptive” and “intended to manipulate search engine results,” then it may take action by applying a duplicate content penalty. So even though it doesn’t happen often, according to Google duplicate content guidelines, you may still end up dealing with a direct penalty if your duplicate content is egregious enough and believed to have been created with malicious intent.
A Google penalty for duplicate content is rare, so the more pressing concern is the relationship between duplicate content and SEO.
2. Index Bloat
Index bloat happens when search engine crawlers access and index unimportant or low-quality content — like those printer-friendly pages I mentioned. This impacts your ability to get your important pages to rank as search engines won’t know which version of your content to suggest to users and may rank a different version than you would prefer. It also impacts crawl budget.
3. Crawl Budget
Google limits how much time it spends crawling sites. The amount of resources Google provides to crawl and index your site is your crawl budget. When you have a lot of duplicate content, you risk wasting your crawl budget on pages that aren’t as important. (Learn how to optimize your crawl budget here.)
4. Keyword Cannibalization
If more than one copy of a page is ranking, then your pages will be competing with each other for the same keywords and visibility. It’s hard enough competing with everyone else, why make it harder by competing with yourself as well?
Ultimately, you can’t just ignore SEO duplicate content issues. Whenever possible, try to consolidate or remove duplicate content. (Learn how to find and fix keyword cannibalization.)
5. Diminishing Link Equity
Let’s say Google decides to rank two of your appreciably similar pages. How do they know whether to attribute all of the content’s value to one page or if the authority, link equity, and trust should instead be split up between both pages? This situation can reduce the SEO value of your content, causing it to underperform.
The link equity of your backlinks will also be divided between the two pages depending on whether other sites choose to link to.
How To Check for Duplicate Content on Your Own Site
Finding duplicate content on your site is free and easy. Use free versions of Screaming Frog and Siteliner to methodically crawl your site and identify any exact or near duplicate pages.
How To Use Screaming Frog To Uncover Duplicate Content
Screaming Frog is a website crawler and SEO audit tool that can help you to identify duplicate content problems on your website. Here’s how to use Screaming Frog to scan up to 500 URLs for free.
1. Crawl Your Site With SEO Spider
First, download and open Screaming Frog. Type the URL of the website you wish to crawl in the ‘Enter URL to Spider’ field, and click ‘Start.’
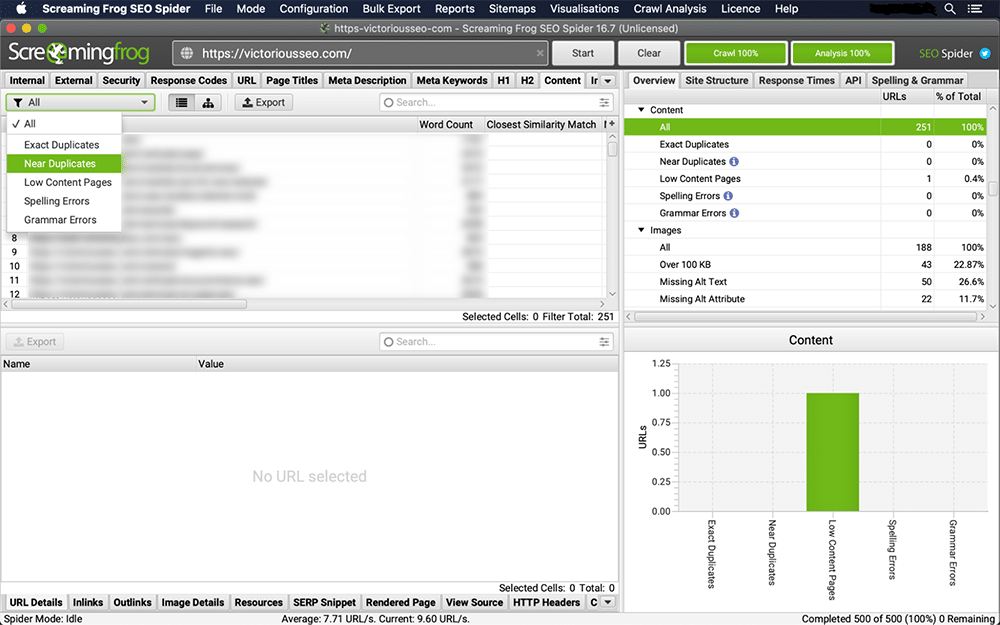
2. Check for Duplicates in the ‘Content’ Tab
Click on the ‘Content’ tab to check for exact duplicates and near duplicates. You’ll be able to see exact duplicates in real time, but you need to perform a ‘Crawl Analysis’ to see the list of near duplicates.
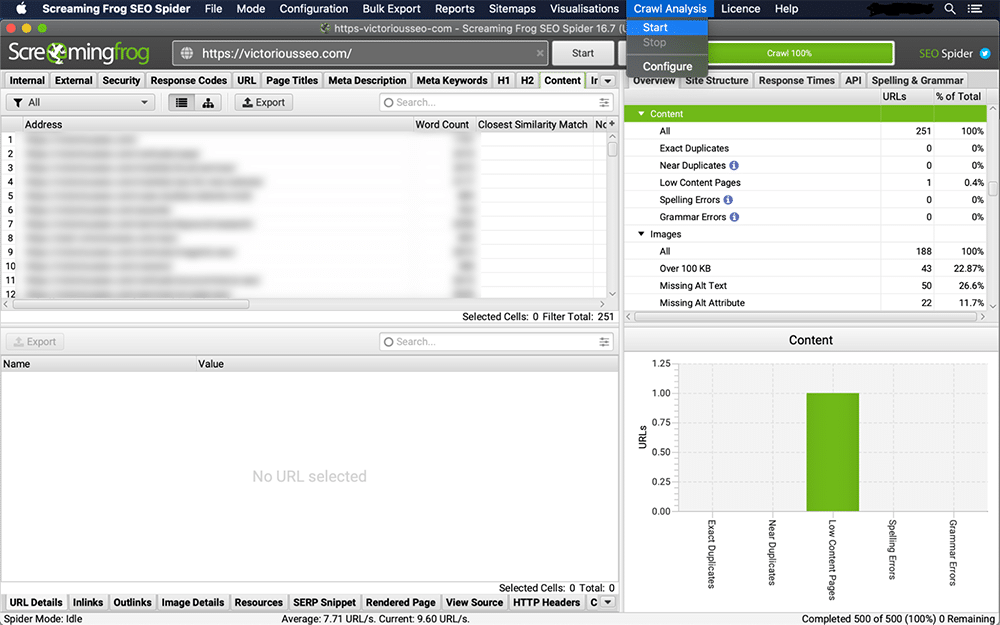
3. Check for Near Duplicates
Click the ‘Crawl Analysis’ tab on the menu bar and choose ‘Start’ from the drop-down menu.
When the crawl analysis finishes, you’ll see the populated near duplicate columns. You’ll know it’s finished because the ‘analysis’ progress bar will read 100% and the near duplicate filter will no longer show a ‘crawl analysis required’ message.
4. View Duplicates Under the ‘Content’ Tab
The ‘Closest Similarity Match,’ ‘No. Near Duplicates,’ and ‘Address’ columns will be populated once the crawl analysis is complete.
The ‘Exact Duplicates’ filter will display pages that are identical to each other based on an HTML code scan. The set similarity threshold determines what qualifies as ‘Near Duplicates.’ To change the threshold, go to ‘Config → Spider → Content. This threshold is set to 90% by default, but you’re free to change it to whatever you prefer.
Now that the scan is done, manually review any page that pops up as an exact or a near duplicate.
How To Use Siteliner to Uncover Duplicate Content
Siteliner is another free tool you can use to scan your website (or any website) for duplicate content. However, the free version will limit you to one use every 30 days and will restrict the number of results to 250 pages. If you need to perform multiple searches or want to see more results, sign up for the premium version.

To check for duplicate content with Siteliner, just enter the URL you wish to search into the search box on their homepage.
Siteliner will then do a sweep of the site and tell you how much duplicate content has been found and highlight what it believes to be your top issues. It’ll also display several more metrics, including some that can be useful for SEO, like average page load time, internal and external links, and inbound links.
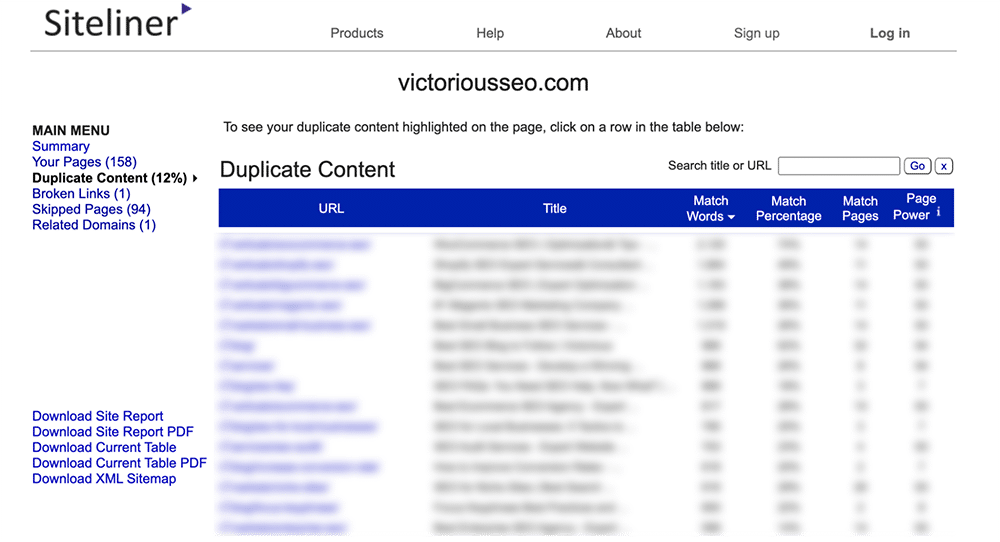
Under the Main Menu, click ‘Duplicate Content’ to see which pages Siteline identifies as having duplicate content.
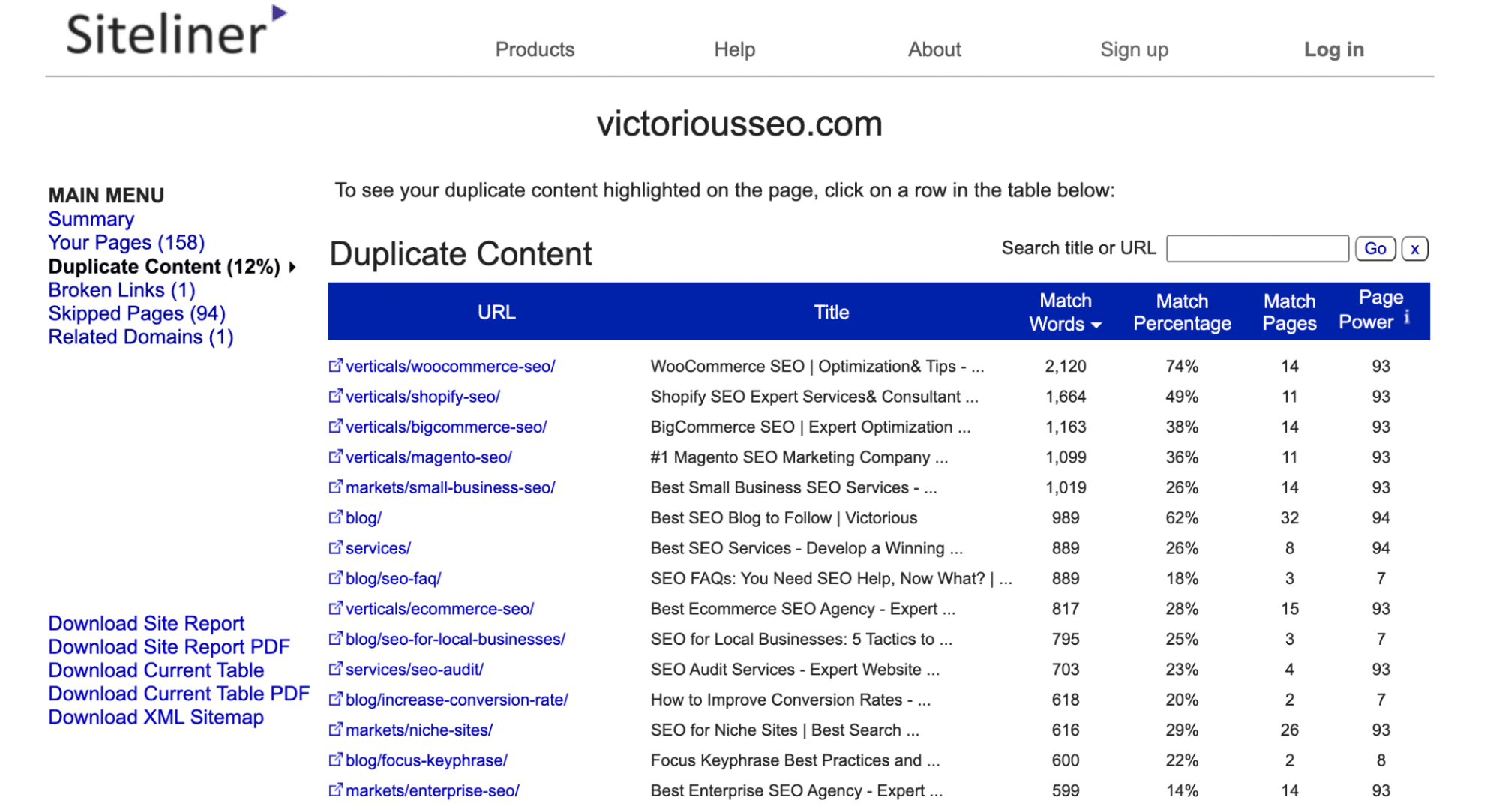
Click on each individual line to see what text is flagged as duplicated.
Note: Siteline will identify headers and footers that appear on multiple pages as duplicate content, so you may get many pages that have a low match percentage because they each share the same menu or footer content.
How To Check if Someone Else Has Copied Your Content
There are also duplicate content search tools you can use to check if someone else on the web has copied your content. Copyscape is a free website content checker tool that’s effective and easy to use.
Just insert a URL into the search box and click the ‘Go’ button right next to it. Copyscape will then perform a web-wide search to see if similar text content exists anywhere else.

If it finds anything, Copyscape will return the results and organize them in a list that looks kind of like Google’s search results. This lets you easily scroll through them and see just how much of your content has been copied. You can think of it kind of like a Google duplicate content checker.
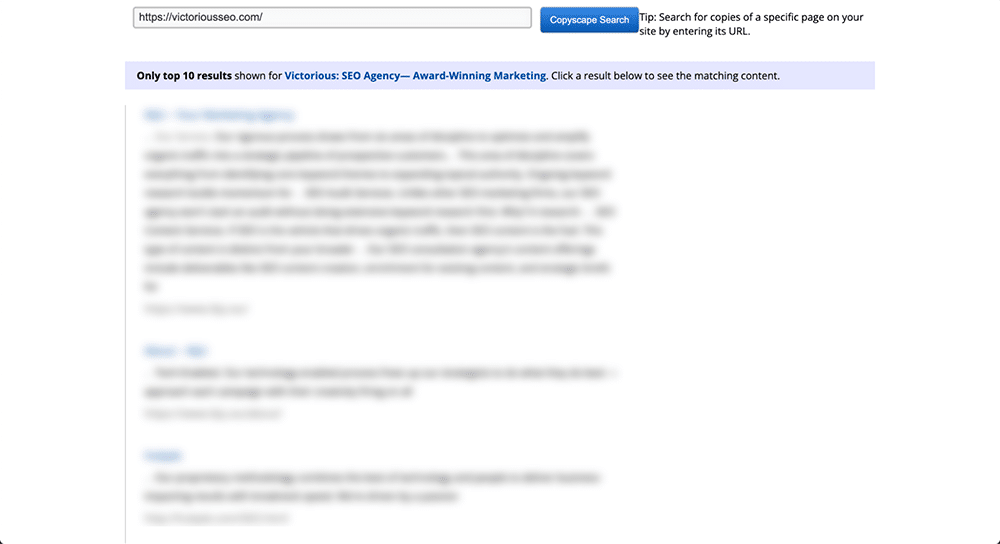
What can you do if you find someone else has plagiarized your content?
First, reach out to the website owner and ask them to either remove the content or to add a canonical link to the original content on your website. If that doesn’t work, submit a DMCA takedown request with Google.
Note: If you’ve intentionally syndicated your content and allowed other websites to publish it, it’ll still show up as a duplicate. That’s why it’s important to require the publishing site to include a canonical link or a noindex tag on the page in order to keep it from competing with your own page in search engine rankings.
How To Fix Duplicate Content
To fix duplicate content issues, identify which copy you want Google to recognize as the original version. You’ll also need to decide whether you want to remove duplicate pages altogether or whether you simply want to tell Google not to index them. Depending on what you decide, there are a few different ways to clean up your duplicate content.
Noindex With Meta Robots Tags & Robots.txt
One way to minimize the impact of duplicate content on your SEO is to manually deindex any duplicate pages by modifying your meta robots tags. To do this, use the meta robots tag and set its values to “noindex, follow.” Apply this tag to the HTML heading of each page you wish to be excluded from search results.
The meta robots tag allows search engines to crawl the links on the page on which it’s applied but prevents search crawlers from including them in their indices.
Why allow Google to crawl the page at all if you don’t want it to be indexed? Because Google has explicitly cautioned against restricting crawl access to any duplicate content on your site. They want to know it’s there, even if you don’t want them to index it.
A noindex tag should look like this when applied to your HTML code:
<head> [code] <meta name=”robots” content=”noindex, follow”> [other code if needed] </head>
The meta robots tag is a simple and effective way to deindex duplicate content and avoid possible SEO problems from having appreciably similar or exact duplicate pages on your website.
If you have entire directories you’d like to block Google and other search engines from indexing, edit your robots.txt file.
301 Redirects
Another way to handle a duplicate content issue is with a 301 redirect. 301s are permanent redirects that forward traffic away from the duplicate page and towards another URL. 301 redirects are SEO friendly and help you combine multiple pages into a single URL so they consolidate their link equity.
When you use a 301 redirect, the duplicate or appreciably similar page will no longer accept any traffic, so only use it when you’re ok with the duplicate page no longer being accessible, like when pruning content. If you still want the page to be accessible, use a meta robots tag to noindex it.
Rel Canonical
Another way to manage your duplicate content is to use the rel=canonical attribute to prioritize pages. Place the rel=canonical attribute inside of the <head> HTML tag to tell search engines that a specific page exists as a copy of another page and that all of the links and ranking power that belong to this page should actually be attributed to the canonical page.
A rel=canonical tag looks something like this when applied to your HTML code:
<head> [code] <link href=”URL OF PRIORITIZED PAGE” rel=”canonical” /> </head>
You can also use a self-referential canonical tag to indicate you want a particular page treated as the original version.
Remove URLs from Your XML Sitemap
Your XML sitemap should only include URLs you want indexed. If you aren’t using a dynamic URL that automatically updates your sitemap, you’ll need to manually edit your sitemap and remove any URLs you noindex or redirect.
Remove URL in Google Search Console
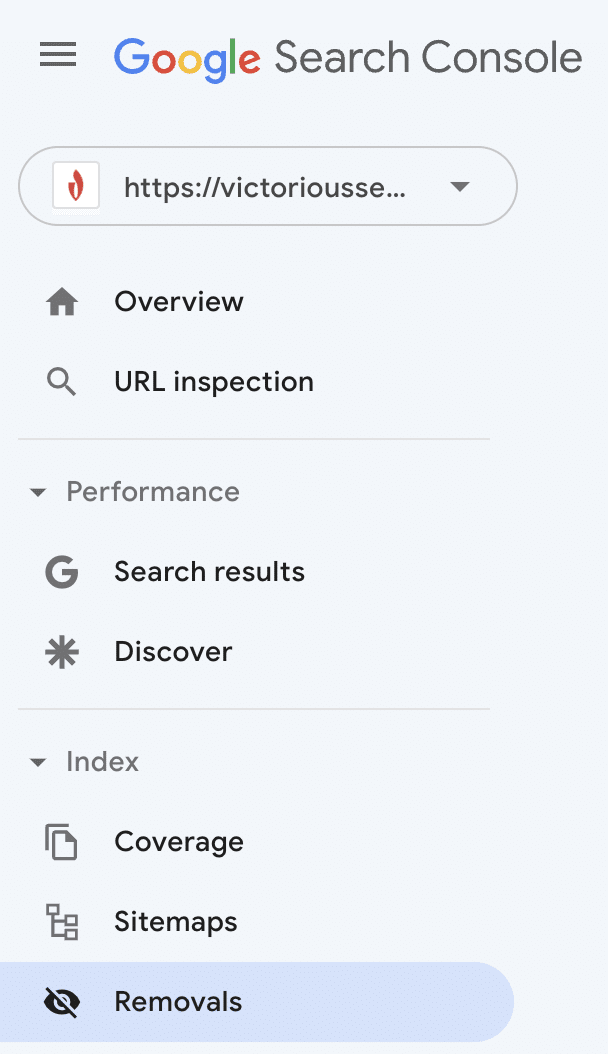
If you choose to redirect a page or restrict indexing, request Google remove that URL from its index.
Sign in to your Google Search Console and select ‘Removals’ from the left-hand menu.
A box will pop up letting you know that submitting a URL will strike it from Google’s index for just six months. After that time, if Google crawls your site and encounters the URL, it’ll be reindexed unless it has been redirected or blocked by a robots tag. If you have multiple URLs that share a prefix, you can also submit the prefix to temporarily remove all of the URLs from Google’s index.
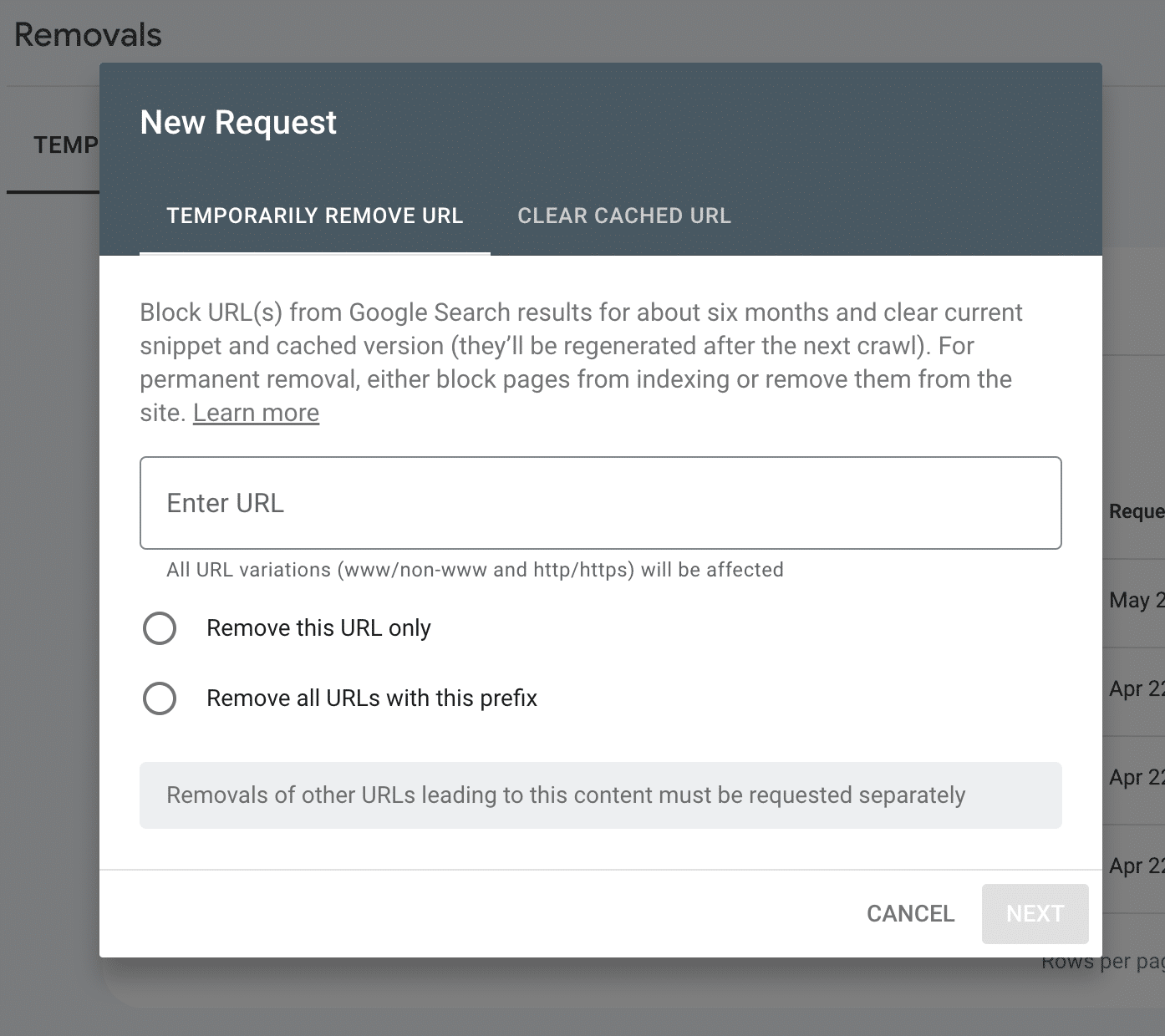
After six months, Google will try to crawl your URLs again. If you’ve properly redirected or noindexed them, they will no longer appear on the search engine results page (SERP).
Need Help Identifying Tech SEO Issues?
Looking to improve your site’s ability to rank? Partner with a data-driven SEO agency that will work with you to identify technical SEO issues on your website and develop a winning SEO strategy to help you climb up the SERPs. Book a free SEO consultation today and see what we can do for you!




