
It may seem counterintuitive, but not every page on your website should appear in search results. Search engine optimization (SEO) strives to increase search visibility and organic traffic — and sometimes, you can best achieve that goal by restricting which content can appear in search results.
If you’re scratching your head or calling my bluff, read on to discover the value of noindexing a page or subdirectory and how to implement noindex tags.
What Does Noindex Mean?
The term “noindex” is a special directive in a robots meta tag that tells search engine crawlers to exclude the page from search engine result pages (SERPs). That means searchers will not be able to access the page via search, though they can still access it if you link to it from your other pages.
A valuable part of any technical SEO strategy, robots meta tags allow you to exclude pages that don’t provide value to searchers or that hold information you don’t want to appear in search results, like:
- Confirmation and thank-you pages
- Login pages
- Privacy policy or terms of service page
- Gated content
- Error messages
Robots Meta Tag vs. Robots.txt vs. X-Robots Tag
Robots meta tag is often confused with robots.txt file and x-robots tag. All three give instructions to search crawlers about pages and are part of the robots exclusion protocol (REP). More simply put: They tell Google what to put into Google Search and what to keep out of it, as well as which pages they should crawl. However, they can’t and shouldn’t be used interchangeably.
Robots Meta Tag
A robots meta tag is added to the <head> section of a particular web page and only passes instructions about that specific page. Often called a noindex tag or a noindex meta tag, the robots meta tag can do more than just tell a search crawler not to index a page.
It can also be used to ask crawlers not to follow links, translate a page, block a specific search bot, or keep a cached link from appearing in SERPs.
Common robots meta tag directives include:
- Noindex, nofollow — <meta name=”robots” content=”noindex, nofollow”>
Googlebot and other web crawlers may access the page, but they should not index it or follow its links. - Noindex, follow — <meta name=”robots” content=”noindex”>
Googlebot and other web crawlers may access the page and follow the links on it, but they should not index the page itself. You don’t need to include “follow” in the meta tag since that’s the default.
Robots.txt
Robots.txt is a file that allows site owners to tell search engines which parts of their site they don’t want crawled. It’s like a personal Do Not Disturb sign for your website hanging out on the root directory of your domain or subdomain.
A robots.txt file is best for blocking entire subdirectories from being accessed and crawled rather than for individual pages. Use it to block search crawlers from accessing and indexing:
- Internal search pages
- URL parameters
- Forums where user-generated spam can cause issues
- Internal subdirectories, like those that are employee-only
Follow these steps to create a robots.txt file, and be sure to link to your XML sitemap.
If you link to a page included in your robots.txt file, you may want to add a noindex meta tag to it as well to ensure it doesn’t show up in search results. Remember — robots.txt only blocks crawlers from accessing a page, not from indexing it. If pages covered under your robots.txt directives receive external links, search engines may index them. Use a robots meta tag in conjunction with the robots.txt file to avoid this.
X-Robots Tag
To block a PDF, video, or image from appearing in SERPs, use an x-robots tag. The same directives specified for robots meta tags are used for x-robots. However, unlike the robots meta tag, which lives in a page’s HTML header, an x-robots tag is placed in the HTTP header response.
The directive looks like this:
X-Robots-Tag: noindexWhen To Noindex a Page
Here are four reasons you should noindex a page:
1. Curb Index Bloat
Index bloat happens when Google indexes pages with little-to-no value for searchers. These extraneous pages detract resources from more valuable pages. Use a robots meta tag to manage which pages appear in search results.
2. Eradicate Keyword Cannibalization
Keyword cannibalization happens when two pages share a similar keyword and search intent, thus causing them to compete against each other in SERPs.
If you have two pages cannibalizing each other and want to keep both without changing their content, noindex one. That said, you should only do this if the page you are noindexing does not drive traffic from keywords that the other page does not. In a situation like this, you may need to rework content on one or both of the pages to solve the cannibalization issue.
3. Protect Gated Landing Pages
When you offer a high-value resource to customers in exchange for contact information, make sure it’s not accessible any other way. Add a robots meta tag to noindex the page and keep it from appearing in SERPs.
4. Exclude Unpopular Products from Search
Ecommerce sites often carry products to serve certain customers even though there isn’t too much demand for them. For example, a car parts retailer or another technical company may have products for particular models or rare equipment. If these product or category pages are not driving organic traffic, they can generally be noindexed.
How To Noindex a Page
To noindex a page, add a ‘noindex’ tag in the HTML head section or response headers of your page to tell search engines not to include the page in search results. Make sure the page isn’t blocked or disallowed in your robots.txt file and that search engines can access the page to read the tag.
The noindex tag code is not case-sensitive and looks like this:
<meta name="robots" content="noindex">“Robots” means the directive applies to any crawler, but you can single out crawlers by replacing “robots” with known crawler names, such as “Googlebot” or “bingbot.”
Crawlers will still follow links on the page unless you also add a nofollow command. You might do this to prevent link equity from flowing through the page or to prevent a crawler from following a link to gated content.
To add a nofollow value, separate it from the noindex directive with a comma.
<meta name="robots" content="noindex, nofollow">Note: Before noindexing a page, check whether it has any incoming organic traffic in Google Search Console. If it does, determine how your site can continue to capture this traffic before noindexing the page.
How To Add a Robots Meta Tag to Your HTML Code
- Open the source code of the page you want to noindex.
- Find the header at the top of the page. It begins with <head> and ends with </head>. There will likely be other code in the header, as well.
- Add the robots meta tag on a new line, ensuring it appears between the <head> and </head> tags.
That’s it! If your page is already indexed, you can ask Google to recrawl it by pasting its URL into the URL inspection tool.
Already Indexed? Use the URL Removal Tool
When you add a noindex tag to a new page of content, Googlebot will see the directive when it crawls the page, and it won’t index it.
However, if you’re adding the tag to a page that’s already indexed, the page will continue appearing in search results until it’s recrawled and the bots see the new noindex instructions. You can ask Google to recrawl the URL in Google Search Console via the URL Inspection Tool, but it won’t instantly remove the page from SERPs.
If you need to remove a page from SERP immediately, use the Removals tool in Google Search Console. This will keep pages out of Google search results for about six months. By then, the noindex meta tag should work.
How To Noindex a Page on WordPress
Every page in WordPress is indexed by default. You can use the Yoast SEO plugin to noindex a page in WordPress without writing code. Here’s how.
Click the ‘Advanced’ tab in the Yoast SEO meta box.
Underneath the question, ‘Allow search engines to show this Post in search results?’ select ‘No’ from the dropdown box.
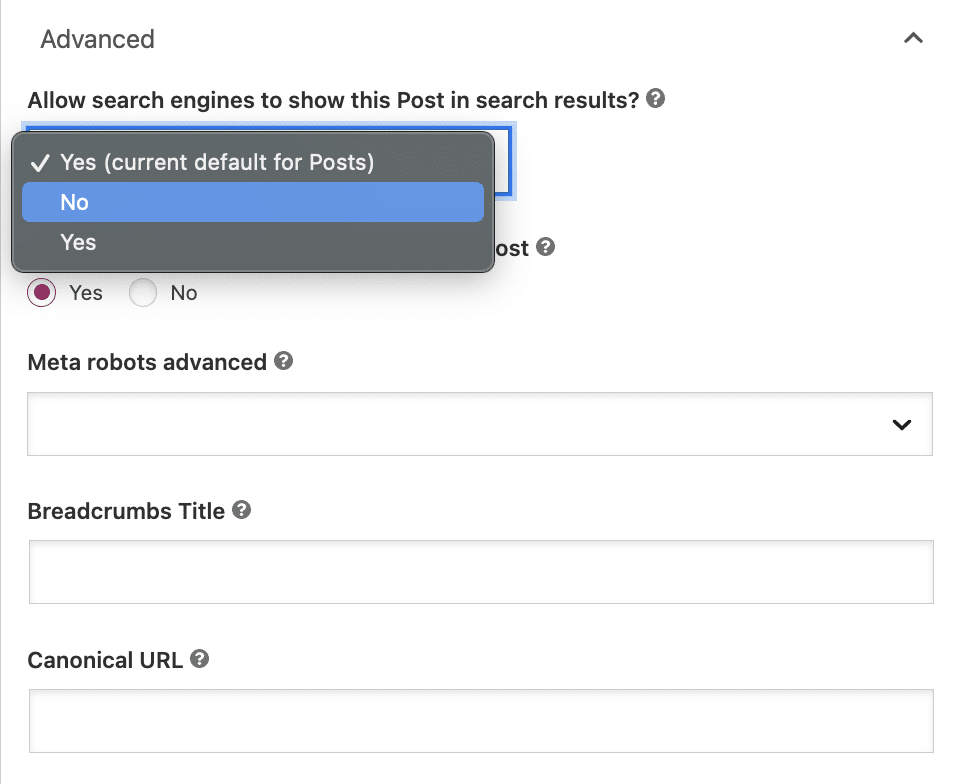
While this setting instructs Google not to index the post, bots will still automatically follow links on the page to crawl other pages.
If you want to add a nofollow directive, select the ‘No’ button under the question: ‘Should search engines follow links on this Post?’
Robots Meta Tag FAQs
Do all search engines obey a noindex directive?
You can expect Google, Bing, and other legitimate search engines to abide by a robots meta tag.
Can I link to noindexed pages?
Yes. The noindex tag tells search bots how to treat a page when crawling and indexing. It doesn’t affect your ability to link to a page. This can be useful for category pages on a blog, which should not show up in search results but can provide the bots with links to valuable pages that should.
When should I use a robots meta tag?
If you have a page that does not offer searchers any value, like a thank you page or a printer-friendly page, noindex it with a robots meta tag to keep it from appearing in SERPs.
When shouldn’t I use a noindex directive?
You can technically solve duplicate content issues and some crawl budget issues with noindex directives, but this is not the best way to do it. Duplicate content is best handled using canonical tags, which concentrate the link equity from the duplicates onto the canonical page. If you’re trying to conserve crawl budget, you should use the robots.txt file to disallow crawling that section of the site.
Do noindexed pages pass link equity?
Yes. Even though a page isn’t indexed, it can still share any ranking authority built up. However, search crawlers must have the ability to follow links on the page for link equity to flow through. If a page is set to noindex and nofollow, it can’t pass link equity.
Does noindexing a page automatically remove it from Google SERPs?
If your page is already indexed, adding a robots meta tag won’t automatically strike it from search results. It takes some time for pages that are already indexed to disappear from SERPs. Search bots need to recrawl the pages to see the noindex tag. For faster results, request that Google recrawl the page and use the URL removal tool.
Uncover Problematic Pages With an SEO Audit
Don’t let thin or duplicate content impact your search visibility. Make sure you’re giving your pages the best chance to rank. Our technical SEO site audit services flag issues like duplicate content, a missing robots.txt file, misapplied robots meta tags, index bloat, and more. Sign up for a free SEO consultation to see how we can maximize your online visibility and help your business grow.

2025 SEO Checklist
Ready to move the needle on your SEO? Download our interactive checklists and
start improving your site today.


