
An optimized website is crucial for ranking on Google and getting found by your target audience. Search engine optimization (SEO) helps make your website more readable and accessible to both search engine crawlers and people.
Every search engine has its own unique web crawlers, but most search strategists focus on just one — Googlebot.
So, what is Googlebot, and how can you optimize your website for it?
What Is Googlebot?
Googlebot is the name of Google’s web crawler. It “reads” web pages and indexes them so they can be served to searchers in response to their search terms.
Googlebot has two critical jobs:
- It continually explores web pages for new links so it can index as much content as possible, and
- It gathers new information about pages to keep Google’s index up to date.
While there’s just one name, there are actually two types of Googlebots: one for mobile (Googlebot Smartphone) and one for desktop (Googlebot Desktop). The former checks how well your site renders on smartphones and tablets, while the latter focuses on the desktop version of your website.
Googlebot optimization is all about making it easier for Google to access, crawl, and “read” your website. While many SEO tactics impact search performance, there are a handful of must-have implementations that improve your site’s “indexability” and can directly influence whether or not your pages are available to Google users. In addition to on-page and off-page SEO tactics, your SEO strategy should include technical SEO objectives to help you increase your chances of showing up in search engine results.
Why focus only on Googlebot? What about the other search engines’ crawlers? Well, since Google currently has 92% of the search market, most of your target audience is likely using it. However, the recommendations that follow should make it easier for all crawlers to read your pages.
How Does Google Indexing Work?
When Google indexes a site, it’s essentially adding it to its knowledge database and making note of what the pages are about, how user-friendly they are, and more. But how does Googlebot even know that a website exists and that it should be indexed?
If you’ve created a website before, you probably noticed that you didn’t get any organic traffic as soon as you published it. That’s because you need to make Googlebot aware of your website so it can crawl your pages. You can do this by submitting your XML sitemap to Google Search Console (formerly Google Webmaster tools).
Googlebot crawls your website using sitemaps and link databases from past crawls. When it finds a new link on your website, it adds it to the list of pages to visit. Both Googlebot Desktop and Googlebot Smartphone will update the index if they come across any broken links or other issues.
This is the index that Google pulls from when it receives a query. It then uses contextual clues from the search to determine how to rank relevant results.
How Often Does Google Crawl My Site?
Google crawls URLs at different rates. While some URLs may be crawled every day, others may only be crawled weekly or monthly. Unless you indicate otherwise in your robots.txt file or in your meta robots tags, Googlebot will attempt to travel to every page on your website and record the information along the way so it can understand your content better and update its index.
While I’ve focused primarily on the Googlebot crawler so far, I do want to note that there are actually multiple Google web crawlers. You can find the full list of Google crawlers here.
If you’re curious about how often Google is crawling and indexing your site, go to your Google Search Console (GSC). You’ll find your Crawl Stats Report under settings.
5 Steps To Optimize Your Site for Googlebot
Follow these five simple steps to keep your site accessible to search engine spiders so your pages can be found in search.
1. Keep Your Code Simple
A big part of increasing your website’s crawlability is to keep things simple. Google won’t crawl Flash, Ajax, frames, cookies, session IDs, or DHTML, and it takes longer to index JavaScript because it has to render it.
When building your website, it’s essential to follow Google’s general and quality guidelines to avoid crawling issues and make it easier to index your pages.
2. Check Your Robots.txt
A robots.txt file tells Googlebot which URLs it can access on your site. Use robot.txt directives to avoid overloading your site with requests and save more crawl budget for pages you want indexed by search engines. Without robots.txt, Googlebot might spend too much time indexing media, resource files, or other unimportant pages you don’t want included in search results. Robots.txt is a protocol-wide directive. You should only have one on your website unless you have multiple subdomains. To manage Googlebot and crawlers on a page-by-page basis, use meta robot tags.
3. Use Internal Linking
Internal links are hyperlinks that take you from one page to another on the same website. They might be navigational (think menus, sidebars, headers, footers), or they can be contextual (placed in the body of a page). To make it easier for Googlebot to find your pages and understand how they relate to each other, use internal linking to emphasize your site hierarchy. All of your pages should be linked together in some way. For example, your homepage should link to your services pages, your case studies, and your blog. Each of those should then link to relevant pages.
Learn more about internal linking best practices here.
Check out your Links Report in GSC to make sure that your most important pages — like your homepage and your services pages — are getting the most links. This indicates to Google that they’re the most important pages on your site.
4. Create an XML Sitemap
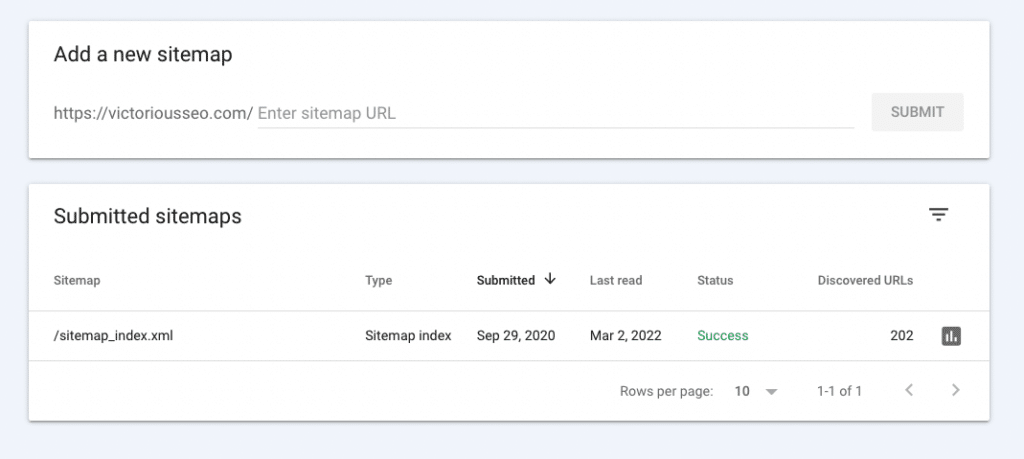
To make it easy for Googlebot to crawl your website, provide an XML sitemap that organizes all your pages for the web crawler to understand your site’s hierarchy quickly. (Not sure what an XML sitemap is, see a sitemap example and learn more here.)
Submit your XML sitemap to Google via GSC during the verification process.
If you’re not using a content management system (CMS) that dynamically updates your sitemap for you, be sure to manually update your XML sitemap and resubmit it when you make changes to your site hierarchy. Just click on “Sitemaps” on the left-hand sidebar. This will help ensure that Google is indexing the appropriate pages on your website.
5. Request Google Indexing
When you publish a new page or make significant updates to existing content, you don’t have to wait until Google finds them — tell Google that you have a new or updated page for them to scan by requesting indexing.

Sign in to your GSC and input the URL you want to be indexed to the left of the magnifying glass icon at the top of the page and hit enter.
Google will note that it’s retrieving data.
And will then tell you whether your page is already indexed.
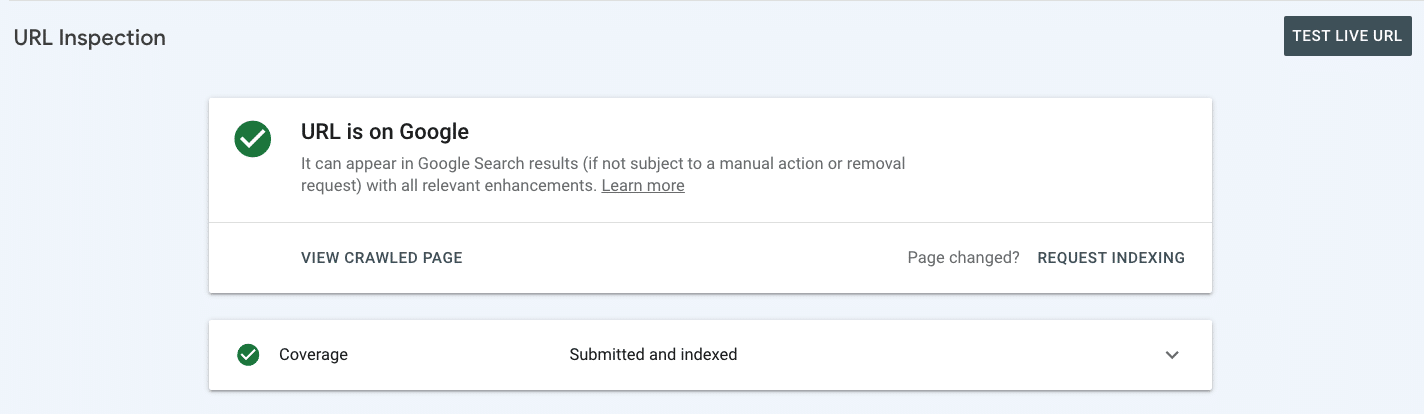
If it’s not, you can request indexing. If your page is indexed and you’ve made significant changes to it, you can also request indexing.
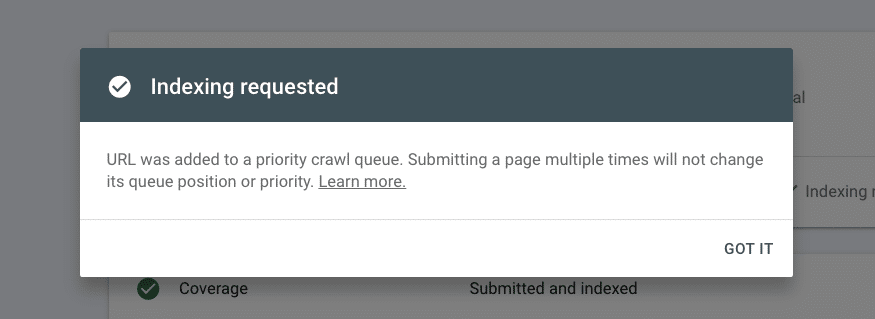
If you add pages to your site frequently, like a new blog post or product page, make this process part of your best practices so you can ensure all your pages are indexed without delay.
Recommended Reading
Four Ways To Analyze How Googlebot Crawls Your Site
Once you’ve optimized your site to make it easier for a search engine crawler to read, you’ll want to double-check that it’s properly crawled and indexed.
Crawl Stats
Your crawl stats show how many total crawl requests Googlebot has sent to your server and when and whether it encountered any issues.
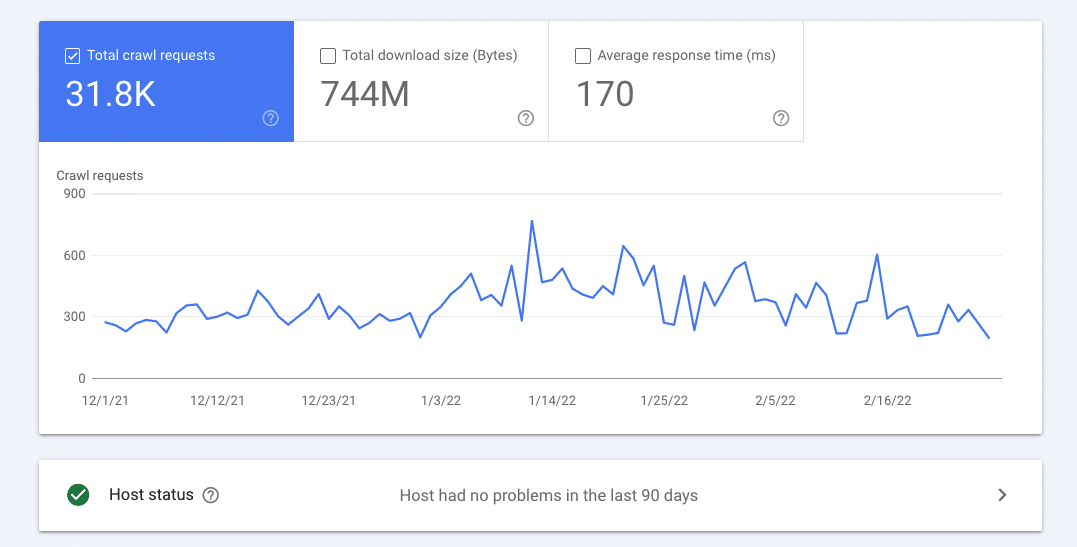
Your crawl stat report in Google Search Console also shows what Googlebot found (crawl responses), file types it encountered, whether Googlebot was discovering new pages or reindexing old ones, and which Googlebot types have been used to crawl your site.
Clicking on a line item in your crawl stat report will provide additional information. For example, if you want to find out which pages are returning a 404 error, click on that line in the crawl responses box to be taken to a list of URLs that Googlebot could not find and when it last attempted to crawl those pages.
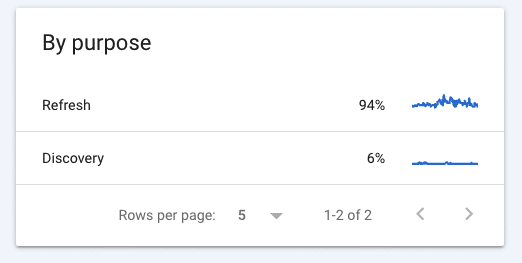
By clicking on the “refresh” or “discovery” line items under Crawl Purpose, you can see which URLs Googlebot has recently indexed. If you see that your most recent pages haven’t been indexed, you can easily submit them using the search bar at the top of the report.
Crawl Errors
Crawl errors occur when search engines are unable to access one of your pages. You can identify two types of Googlebot crawling errors on your Crawl Report that can negatively impact your SEO:
- Site Errors: When you have a site error, Googlebot may not be able to crawl your site. Site errors may be caused by missing or inaccessible robot.txt files, DNS resolution failures, or server connectivity issues.
- URL Errors: With a URL error, Googlebot is unable to crawl a particular page. You can have multiple URL errors at once.
Moz does a great job of sharing how to fix crawl errors.
Blocked URLs
If there are sections of your site that you don’t want Google crawler to access, you can specify those directories in robots.txt to provide information on how robots should index your content.
Check your GSC to see the number of blocked URLs Google recognizes to make sure your robots.txt is working. If the number of blocked URLs is lower than it should be, you’ll need to edit your robots.txt file. Conversely, if the number is higher than it should be, there might be pages inadvertently blocked from crawling that you want to appear in search results.
URL Parameters
URL parameters, also known as query strings, allow you to add additional info to the end of dynamic URLs. If you’ve visited paginated content, such as product search results on an ecommerce site, you’ve likely seen “?page=2” or something similar at the end of the page’s URL. That’s a URL parameter. These parameters can also be used for:
- Content filters
- Translations
- Site searches
- Tracking
If you want to use parameters in your URLs, consider whether you want them to be accessed and indexed since they can lead to significant issues like duplicate content, wasted crawl budget, and tracking problems.
You can follow these steps to block the crawling of parameterized content.
Learn More About Google Tools for SEO
Google offers a variety of tools to help you measure your site’s performance. Take advantage of these to monitor and improve your SEO strategy.
Our Google tools resources will walk you through each of the free SEO tools from Google and break down technical concepts into actionable and easy-to-understand chapters brimming with additional resources.



