
Before you can gain visibility in search engines, you have to roll out the welcome mat and allow Google’s search crawlers to gather information about relevant web pages. Occasionally, Googlebot runs into problems, but Google Search Console (GSC) can tell you what’s holding pages back from being indexed.
Truthfully, some of the error messages sound like a foreign language (Duplicate without user-selected canonical? Alternate page with proper canonical tag?). Join me for a jargon-free crash course on indexing errors. I’ll explain how to use GSC’s indexing report, what common error messages mean, and how to fix them so you can get your pages indexed and help them send traffic to your site.
What Is the Page Indexing Report?
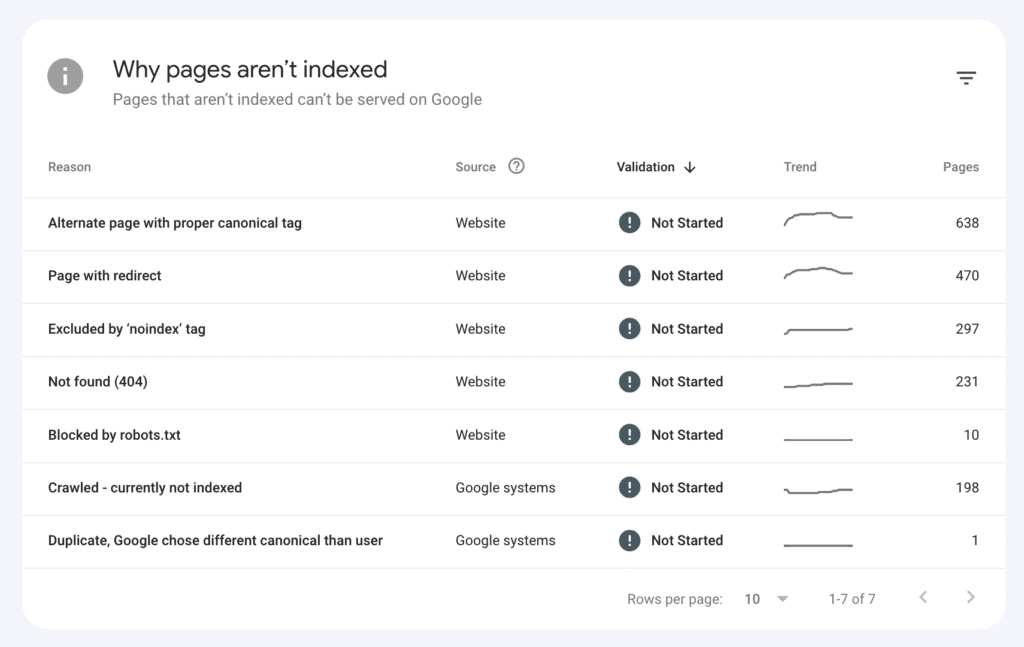
Google Search Console offers an array of tools to troubleshoot your website, detect structured data issues, and evaluate Core Web Vitals. Another essential tool is the Page Indexing Report, which indicates which pages of your site have been excluded from the index and why. Use this report to ensure your important pages can be found in the search engine results pages (SERPs).
To access this report:
- Sign into Google Search Console using your Google account. If you’re working with SEO agency experts, add them as users so they can access the report as well.
- Go to the Index menu and click Pages. You’ll see an overview of the number of indexed and non-indexed pages.
- Scroll to see a list of current indexing errors and the number of affected pages for each.
- Click on a specific warning message to see details of the URLs with issues.
Possible Errors & How To Fix Them
Before you dive in, I should clarify that not all of your pages need to be indexed. Also, while you should fix some errors, other errors merely confirm redirects and other directives you may have implemented on your site.
All right — let’s get those pages indexed.
Duplicate Without User-Selected Canonical
Here’s some background on this one: When your site has pages with similar content, only one of those pages should appear in search results. Designate the preferred page using a canonical tag. When similar content exists, a canonical should indicate which version is the primary source of the content — unique, informative, and most relevant.
The “Duplicate Without User-Selected Canonical” error means you didn’t implement a canonical tag for a duplicate page. Google took the liberty of choosing the page that appears in the SERPs.
How To Fix Duplicate Without User-Selected Canonical Errors
- If Google selected the appropriate canonical page, that’s great. I still recommend you update your page to include the appropriate canonical URL. It’s a best practice to have self-referential canonicals on your pages unless you want a different page to serve as the canonical page.
- If Google chose the wrong canonical page for a URL and you think it shouldn’t have, add the appropriate canonical to your page. Then compare the content on the pages. Is the content of the page you consider as the primary source low quality or irrelevant? Is the intention misaligned with the keywords on the page or the overall topic? Make sure the content on the page is substantially different; otherwise, your page won’t be indexed.
Duplicate, Google Chose Different Canonical Than User
In this situation, Google is ignoring your preferred canonical page because it’s not similar enough to the page showing the error message (known as the tested page). It’s selected another page that it believes should be the canonical URL.
How To Fix Duplicate, Google Chose Different Canonical Than User Errors
- Use the URL Inspection Tool to see which page Google has chosen as canonical — you can see the canonical information under the Page Indexing drop-down.
- Review the tested page and your preferred canonical page and ensure the content is similar.
- Review the tested page and Google’s preferred canonical page and find ways to distinguish between them.
- Make sure your preferred canonical URL is in your sitemap.
If the page Google chose is also the tested page, Google added a self-referencing canonical tag. In simpler terms, the page doesn’t have a duplicate and should be indexed.
Alternate Page With Proper Canonical Tag
This message lets you know Google found alternate pages on your site — for example, mobile and desktop versions of the same page. It designated one as canonical, so they don’t both appear in search results.
How To Fix Alternate Page With Proper Canonical Tag Errors
In most cases, you only want one of the pages indexed, so you don’t need to do anything.
For both pages to be indexed, the content must be significantly different. You can also remove the canonical tag that Google added, but if you haven’t made the pages unique, Google will probably issue another error message the next time it crawls the page.
URL Blocked by Robots.txt
A robots.txt file tells Googlebot which URLs it can crawl and index. The “URL Blocked by Robots.txt” message means the crawler followed your instructions and went onto another page.
How To Fix URL Blocked by Robots.txt File Errors
- If you want the page crawled and indexed, update your robots.txt file by removing the disallow directive associated with the page or directory.
URL Marked Noindex
When you don’t want a page indexed, place a noindex tag in the HTML or header of a page. When Google follows this directive, you’ll see the “URL Marked Noindex” status on your coverage report.
How To Fix URL Marked Noindex Errors
- If the page shouldn’t be indexed, you don’t need to do anything further as long as you have the noindex meta tag on the page.
- If the page should be indexed, remove the noindex tag and request that Google reindex the page with the URL inspection tool.
Server Error
A server error means Googlebot couldn’t retrieve the page. Your server may have been down or overloaded with requests, or a firewall or server settings blocked the crawler.
How To Fix Server Errors
- Use the URL Inspection Tool to check the page in real time and see if the error was temporary.
- Review GSC’s Crawl Stats Report for problems with your site’s availability.
- Ensure security settings aren’t preventing crawling.
- Whitelist Google’s IP addresses.
- Review server configurations.
- Optimize code and introduce caching solutions to accommodate server demand.
Redirect Error
A redirect error means there was an issue when Googlebot tried to follow a redirect from one page to another. There may be too many redirects in the chain or a redirect loop without a final destination.
How To Fix Redirect Errors
- Run a site audit using Google Lighthouse to find redirect issues.
- Simplify redirect chains by reducing the number of redirects between the original URL and the final destination.
- Remove unnecessary redirects.
Blocked Due to Unauthorized Request (401)
The “Blocked Due to Unauthorized Request (401)” error means Googlebot couldn’t access a page because of permissions. This occurs if login credentials are needed or IP addresses are blocked.
How To Fix Unauthorized Request (401) Errors
- Review authentication settings and restrictions.
- Permit Googlebot to access the page. You can verify a crawler is indeed Googlebot by matching its IP address to Googlebot’s IP addresses.
Not Found (404)
A 404 error occurs when Googlebot tries to access a deleted page or follows a link to a page that doesn’t exist. If the URL shouldn’t exist, you don’t need to fix the error. The 404 error doesn’t impact ranking, and Google eventually stops trying to crawl it.
How To Fix Not Found (404) Errors
- Remove deleted pages from your sitemap.
- Use a 301 redirect if a page has moved or merged with another page.
- Redirect commonly mistyped URLs to the appropriate page.
- Make sure you haven’t inadvertently removed pages that should be accessible.
Soft 404
A soft 404 occurs when Google assumes a page doesn’t exist because of content issues. This can be due to empty templates, lack of content, missing scripts, problems with file permissions, broken database connections, and large files that aren’t loading.
How To Fix Soft 404 Errors
- If you want the page indexed, improve the content, ensure it loads properly, and submit it for reindexing.
- If you don’t want the page indexed, place a noindex tag in the page header.
- If you have removed the page, implement a 301 redirect.
Crawled – Currently Not Indexed
Sometimes a page is crawled but not indexed. Note the word “currently” in the title — it does take time for report data to update. Occasionally, a page isn’t indexed at all because Google feels it’s a duplicate or not valuable to readers.
How To Fix Crawled – Currently Not Indexed Errors
- Use the URL Inspection Tool to check if the page is indexed in real time.
- If the page isn’t indexed and has sparse content, expand it to provide more depth and relevance for your website visitors.
- If the page has thin content because it’s part of a series of pages, provide a “View All” page as a canonical URL.
Discovered – Currently Not Indexed
This message means Google knows your page exists but will be back later to crawl it. This can happen when your server is overloaded with requests. It’s also possible you have too much content — known as index bloat— and Googlebot didn’t have enough crawl budget to get to the page.
How To Fix Discovered – Currently Not Indexed Errors
- Reduce index bloat to ensure Google isn’t wasting time crawling unnecessary pages.
- Optimize internal linking so there are multiple ways to discover your pages.
- Request the page be indexed so Google tries again.
Blocked Due to Access Forbidden (403)
If you have a URL that requires authentication to access it, you’ll get a message that Googlebot was blocked due to a 403 Access Forbidden error.
How To Fix Blocked Due to Access Forbidden (403) Errors
- If you want the page indexed, remove the authentication requirement so search crawlers can access it.
- If you keep the login requirement, verify and allow crawlers that match Googlebot IP addresses.
Page With Redirect
When you redirect users to another page, the original page won’t be indexed, and GSC notes it’s a “Page With Redirect.” If this redirect is correct and working as you intend, you don’t need to do anything.
How To Fix Page With Redirect Error
If the page shouldn’t be redirecting and you do want it indexed, remove the redirect so Googlebot stays on the page and crawls it.
Page Indexed Without Content
Occasionally, Google has trouble reading content but indexes the page anyway. The problem with this error message is that Google can’t interpret the meaning of your page to match it to relevant queries.
“Page Indexed Without Content” can occur when a page is cloaked — meaning you have different versions for search engines and users. The page might also be in a format that Google can’t process.
How To Fix Page Indexed Without Content Errors
- Use the URL Inspection Tool to see what the page looks like to Google.
- Ensure the content renders properly.
- Make sure the page isn’t blank or empty.
- Publish content in an accessible format.
- Avoid cloaking practices. These practices are manipulative and can negatively impact the website’s overall ranking and even lead to the site’s removal from indexes or a complete ban from the SERP.
URL Blocked Due to Other 4xx Issue
When a browser or bot tries to access your site and the server can’t fulfill the request, it sends a 4xx status code. Google won’t index any pages with 4xx errors. In addition to the warnings discussed above, you may also have 400 (bad request), 410 (gone), 411 (length required), and 429 (too many requests) errors.
How To Fix URL Blocked Due to Other 4xx Issue Errors
Use the URL Inspection Tool to learn about the type of error on the page, or type the URL into a browser to see the result. After fixing the error, resubmit the page for indexing.
- A 410 error usually indicates a file or resource has been removed.
- A 411 error requires you to define a content-length value for a page so that the server knows the size of the incoming request.
- A 429 error typically means your website can’t handle the number of requests made. Reconfigure the rate-limiting settings on your site.
Blocked by Page Removal Tool
You can temporarily remove pages from Google’s index if there’s information you want to quickly remove from the SERPs. Googlebot won’t crawl the site, and you’ll see the “Blocked by Page Removal Tool” status.
How To Fix Blocked by Page Removal Tool Errors
- Revise page content as needed. Removals are temporary, and pages reappear in the SERPs after about six months.
- Go into the Page Removal Tool and cancel the request if you want the URL to appear in the SERPs sooner.
Indexed Though Blocked by Robots.txt
While a robots.txt file specifies which pages of your site you don’t want crawled to avoid overloading your site with requests, Googlebot occasionally finds its way to a page through external links. As a result, Google may index the page.
How To Fix Indexed Though Blocked by Robots.txt Errors
- If you want the page indexed, update the robots.txt file to allow Google to crawl it.
- If you don’t want the page indexed, remove the robots.txt block and instead apply a noindex tag.
Confirm Your Fix With Google
Once you’ve addressed any issues keeping your pages from being indexed, make sure to let Google know! For each issue you address, click the “validate fix” button
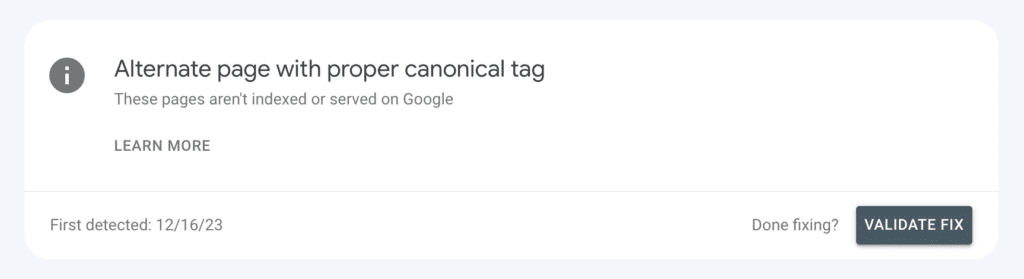
Google will note when fix validation commenced.
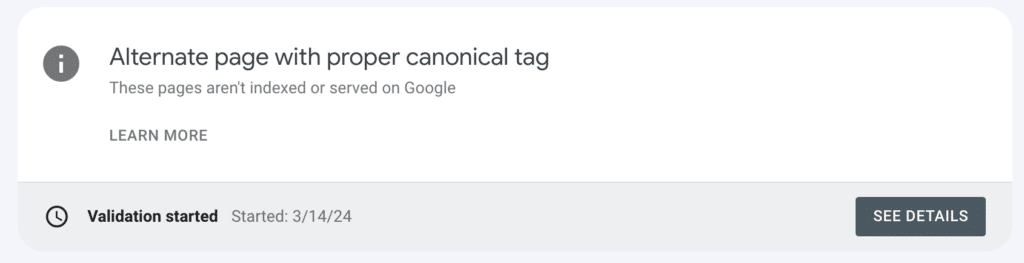
Then, it will assess whether you adequately addressed the issue. If everything looks good, the issue count will eventually decrease to zero, and the issue will drop to the bottom of the Page indexing report. Google will also email you to let you know the validation is complete.
If issues remain, even on just one page, you’ll receive an email informing you that issues persist. The count will be updated, though, so you can further troubleshoot the specified URLs if needed.
Boost Your Site Performance With a Personalized SEO Strategy
Google Search Console is a powerful tool for improving online visibility, especially when linked to Google Analytics. However, paving the way for Googlebot to crawl your site is only one step. There are many other SEO pieces that must fall into place for your site to shine in search results. If you’d like an experienced partner to guide you through the complexities of SEO, get in touch with Victorious for a free consultation.


